
티스토리 뷰
[논문 리뷰] A TIME SERIES IS WORTH 64 WORDS:LONG-TERM FORECASTING WITH TRANSFORMERS
hyuna_engineer 2024. 3. 12. 17:16
Abstract
모델 : channel-independent patch time series Transformer (PatchTST)
변수가 여러 개인 시계열 예측(time series forecasting)과 자기 지도 학습 표현 학습(Self-Supervised Representation Learning)에 대해서 Transformer 기반으로 발전시킨 모델에 대한 설명한 논문이다. 2가지의 주요 구성 요소가 있다.
1. 시계열 데이터를 작은 부분 단위로 쪼개어서, 각 부분을 토큰화하여 Transformer 모델의 입력으로 사용한다.
2. "채널 독립성(channel-independence)"은 다수의 시계열 데이터가 각각의 채널에 할당되는데, 각 채널은 하나의 단변량 시계열을 포함하며, 이러한 시계열들이 모두 같은 임베딩과 Transformer 가중치를 공유한다.
이러한 patching design은 3개의 이점을 가진다.
1. 원본 데이터의 지역적인 특성이 의미를 잃어버리지 않고, 유지된다.
2. 이전 데이터의 look-back window 내에서 attention map의 계산과 메모리 사용량이 입력 데이터 크기의 제곱에 비례하여 줄어든다. 이전의 모든 데이터를 고려할 때 어텐션 메커니즘은 계산 및 메모리 부담이 매우 크지만, 주어진 참조 창 내에서만 관련성을 고려할 경우 계산 및 메모리 사용량이 상대적으로 감소합니다.
3. Long - term, 장시간 예측에서의 정확성을 올린다.
Introduction
Deep model은 예측 task에서도 뛰어난 성능을 보이며, 표현 학습(abstract representation)에서도 좋은 성능을 보인다. 이는 추상적인 특징, 구조를 학습한다는 의미이다. 이와 관련한 deep model인 Transformer은 NLP, CV 분야에서 꾸준히 우수한 결과를 가져온다. 이를 time series data에 적용했을 때도 좋은 결과가 나왔다. 하지만, 최근의 논문을 보면 ( 링크 ), 그냥 linear model이 transformer 보다 좋은 결과를 가져오면서, transformer 모델이 시계열 분석 예측에서는 필요성이 떨어진다는 의견이 대두된다. 저자는 channel-independence patch time series Transformer (PatchTST) 모델을 제시하면서 transformer 모델을 time series data에 적용해서 linear model보다 좋은 효과를 얻게 했다. 이 모델에서 중요한 점은 abstract에서 말했듯이 두 가지가 있다.
1. patching
시계열 데이터 예측은 각 다른 step마다 data 사이의 상관 관계를 파악하는 것이 주요점이다. 그러나, 각 step은 semantic meaning을 갖지 않아, 즉, 단어와 문장처럼 transformer에 최적화된 data는 아니라서, 시계열 데이터들의 상관관계를 파악하려면, local semantic info를 직접 뽑아줘야 한다. 이전 연구 대부분은 점 단위의 입력 토큰 또는 series(연속)로부터 수동으로 생성된 정보만을 사용한다. 이에 대조적으로, 저자는 시간 단계를 sub-series 수준 patch로 집계함으로써 지역성(localization)을 강화하고 점 단위에서 제공되지 않는 포괄적인 의미 정보를 포착합니다.
2. channel-independence
다변량 time series는 multi-channel 신호를 가지며, transformer 모델의 input token은 각 채널 또는 다양한 채널의 데이터로부터 얻는다. "Channel-mixing"은 입력 토큰이 모든 시계열 특징의 벡터를 가져와 임베딩 공간에 정보를 혼합하는 경우로, 저자는 이와 반대인 " Channel-independence"은 각 입력 토큰이 단일 채널에서만 정보를 포함하는 경우다.
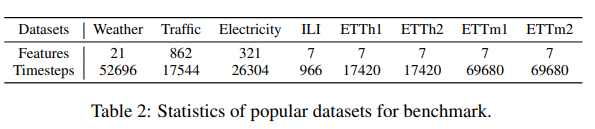
Traffic dataset (862 time series data)로 진행한 결과는 다음과 같다.
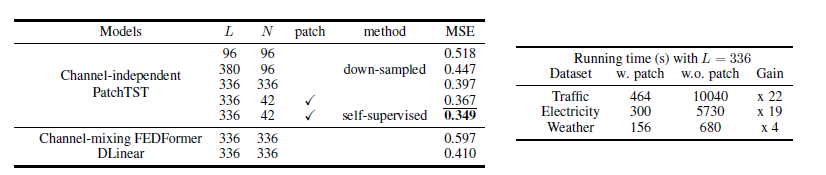
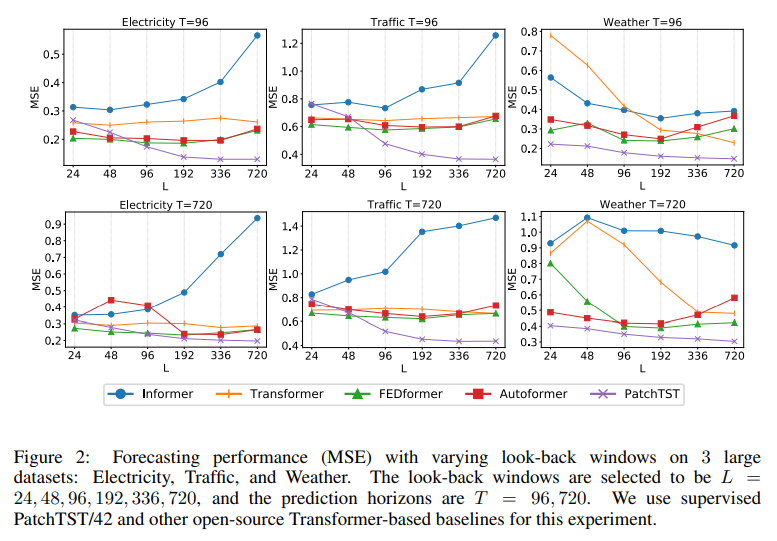
PatchTST는 다음 3가지의 이점이 있다고 한다.1. 시간과 공간 복잡성 감소 : 기존의 transformer는 O(N^2) 복잡성을 가지고 있는데, (N : input token의 갯수) patching을 적용하면 N ≈ L/S으로 복잡성을 제곱으로 감소시켰다. 2. 전방 시차 창(look-back window) = 모델이 이전 시간 단계에서 발생한 데이터를 고려하는 시간 범위. 이는 모델이 더 오랜 기간 동안(L)의 데이터를 고려하고 이를 학습하여 더 장기적인 패턴이나 상관 관계를 파악할 수 있게 했다. 96 ->336 으로 이렇게 L을 늘리면 memory와 사용량의 비용을 소비시키게 된다. 또한 시계열 데이터는 종종 시간적으로 중복되는 정보를 많이 포함하기 때문에, 이전 연구들은 다운샘플링을 사용하거나 dense한 연결을 통해 데이터 포인트의 일부를 무시하려고 했고, 예측 결과도 좋게 나왔다. 저자는 L=380, 4 time step마다 시계열이 샘플링되고 이에 입력 토큰 수, N=
96까지 진행했을 때, 96의 시퀀스 전체를 사용할 때보다 MSE 점수(0.447)가 더 우수하며(0.518), 동일한 입력 토큰 수를 사용하더라도 look-back window가 더 중요한 정보를 전달한다는 것을 보여줍니다. 4 time step마다 시계열이 sampling 되는데, 이러면은 값이 버려질 수도 있는 단점이 있다. 이를 해소하는 방법이 patching이다. 유사한 값을 포함하게끔 group화 해주고, 모델의 계산량을 줄이기 위해 입력 토큰 길이도 줄여준다. Table1 에서 패치 처리를 적용하면 MSE 점수가 L = 336인 경우에 0.397에서 0.367로 더욱 줄어든다.
3. 표현학습의 능력(capability of representation learning) : 성능이 좋은 자기 지도 학습 기술이 등장함에 따라, 데이터의 추상적인 표현을 추출해내기 위해 다중 비선형 추상화 계층을 갖춘 정교한 모델이 필요하다. Linear model처럼 간단한 모델은 제한된 표현 능력으로 인해 이러한 작업, representation 선호되지 않는다. PatchTST 모델로는 Transformer가 실제로 시계열 예측에 효과적임을 확인할 뿐만 아니라, 예측 성능을 더욱 향상시킬 수 있는 표현 능력을 보여준다.
Related Work
1.
Proposed Method
<모델 구조>

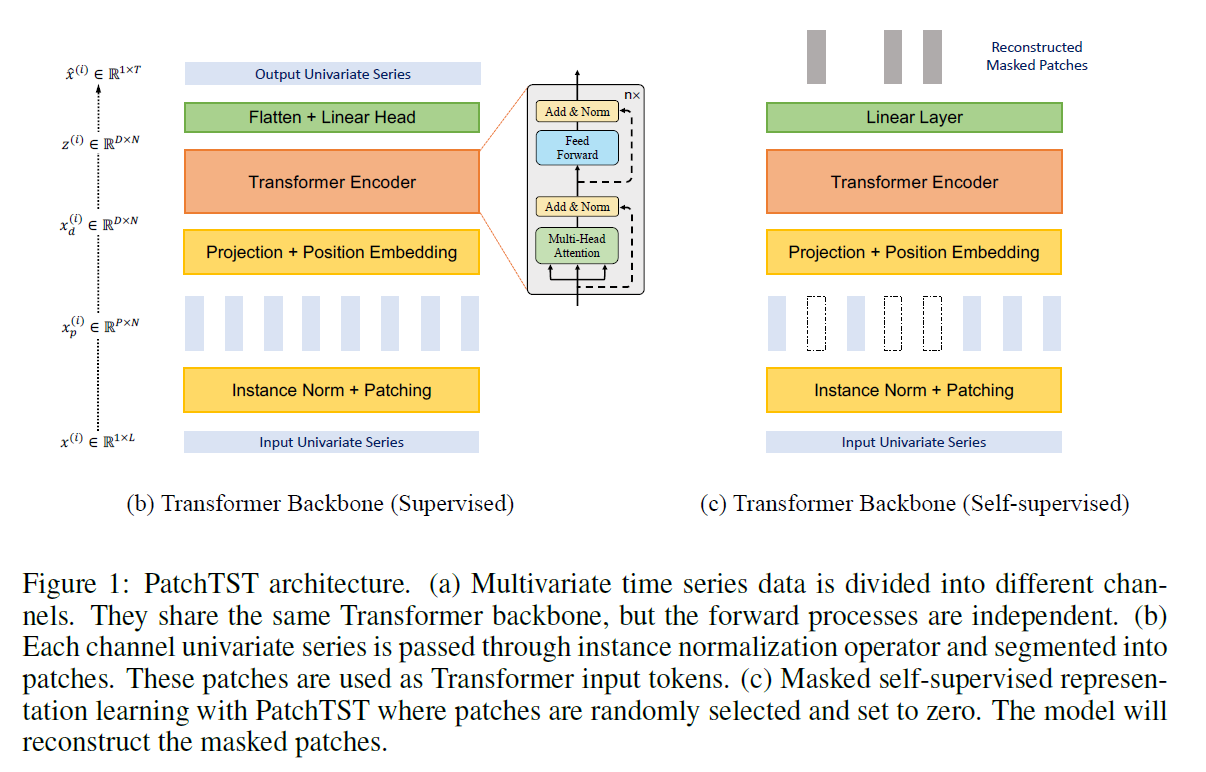
우리가 다루고자 하는 문제는 전방 시차 창(look-back window) 크기가 L인 다변량 시계열 샘플 모음이 있다. 여기서 각 시간 단계 t의 xt는 M 차원 벡터이며, T개의 미래 값을 예측하고자 합니다 (xL+1, ..., xL+T). 논문의 PatchTST는 모델이 바닐라 Transformer 인코더를 핵심 아키텍처로 사용하는 그림 1 에 설명된 대로 구성된다.
<Forward Process>
시작 시간 인덱스가 1인 길이 L인 i번째 단변량 시리즈를 x(i)1:L = (x(i)1, ..., x(i)L)라고 표현한다( i = 1, ..., M). 입력 (x1, ..., xL)은 각각의 단변량 시리즈 x(i)가 R^1×L로 분할되고, 각각의 시리즈는 독립적으로 Transformer backbone에 공급한다. 결과로는 다음과 같이 나온다.

<Patching>
단변량 time series x^(i)가 우선적으로 patcher로 나누어진다. patch 길이를 P로 하며, 겹치지 않는 영역으로 stride를표시하면, 패치 과정에서 패치 시퀀스는 \(x_p^(i) \in \mathbb{R}^{P \times N}\)이며, N= ⌊(L - P) / S⌋ + 2 이다. ⌊⌋는 내림 함수입니다. 패치 전에 원래 시퀀스의 끝에 패딩으로 S개의 마지막 값 x_L^(i)을 붙여서 쓴다. 이렇게 patching 작업으로 N을 L/S으로 근사화시키기 때문에, GPU 메모리와 training 시간을 길게 잡을 수 있어서 예측 성능이 더 좋게 나온다. 이에 대한 결과 또한 table 1에서 확인 가능하다.
<Transformer Encoder>
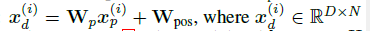
훈련 가능한 Linear projection \(W_p \in \mathbb{R}^{D \times P}\), 학습 가능한 가산 위치 인코딩(learnable additive position encoding) \(W_{pos} \in \mathbb{R}^{D \times N}\)이다. 이를 이제 multi-head attention으로 input으로 넣는다. 이는 query, key, 그리고 value matrices로 전환하는데 이에 대한 식은 다음과 같다.

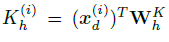



이 Q, K, V를 attention 식에 따라 처리 후 softmax를 거치면서 attention output을 이끌어낸다. 이 multi-head attention block은 BatchNorm layer과 그림 1에 나온 것처럼 residual connection이 있는 feed forward network을 포함한다.
\[ \hat{x}^{i} = (\hat{x}_{L+1}^{i}, ..., \hat{x}_{L+T}^{i}) \in \mathbb{R}^{1 \times T}\]
와 같은 예측 결과를 가져온다.
<Loss Function>
MSE loss를 사용하여 prediction과 groudn trutch의 차이를 계산한다. 식은 다음과 같다.

<Instance Normalization>
각 시계열 step마다 \(x^{i}\) 마다 표준 정규 분포에 따른 정규화 진행.
Representation Learning
자기 지도 표현 학습은 레이블이 없는 데이터로부터 고수준의 추상적인 표현을 추출하는 인기있는 방법이었다. 이 절에서는 PatchTST를 적용하여 다변량 시계열의 유용한 표현을 얻는 방법을 보여주고자 한다. 학습된 표현이 예측 작업으로 효과적으로 전달될 수 있다는 것을 보여줄 것입니다. 자기 지도 사전 훈련을 통해 표현을 학습하는 인기 있는 방법 중 하나로, 마스크된 오토인코더가 NLP (Devlin et al., 2018) 및 CV (He et al., 2021) 도메인에 성공적으로 적용되었습니다. 이 기술은 개념적으로 간단합니다: 입력 시퀀스의 일부가 의도적으로 무작위로 제거되고, 모델은 빠진 내용을 복구하도록 훈련됩니다.
최근에는 마스크된 인코더가 시계열에 적용되었으며, 분류 및 회귀 작업에서 주목할만한 성능을 발휘했습니다 (Zerveas et al., 2021). 저자들은 각 입력 토큰이 i번째 시간 단계에서 시계열 값으로 구성된 벡터 xi인 Transformer에 다변량 시계열을 적용하는 것을 제안했습니다. 마스킹은 각 시계열 내부와 다른 시계열 간에 무작위로 배치됩니다. 그러나 이 설정에는 두 가지 잠재적인 문제가 있습니다. 첫째, 마스킹이 단일 시간 단계 수준에서 적용됩니다. 현재 시간 단계의 마스킹된 값은 전체 시퀀스의 고수준 이해 없이도 즉시 직전 또는 직후 시간 값과 보간하여 쉽게 추론될 수 있습니다. 이는 전체 시그널의 중요한 추상적 표현을 학습하는 목표에서 벗어납니다.
두 번째로, 예측 task 출력 레이어의 설계는 문제가 될 수 있습니다. L 시간 단계에 해당하는 표현 벡터 zt가 모든 M 변수가 있는 출력에 T 예측 경계가 있는 출력으로 매핑되는 경우, 선형 맵을 통해 필요한 매개변수 행렬 W의 차원은 (L × D) × (M × T)입니다. 이 행렬은 이 네 가지 값 중 하나 이상이 큰 경우에 특히 크기가 커질 수 있습니다. 이로 인해 하류 훈련 샘플 수가 부족한 경우 과적합이 발생할 수 있습니다. 저희가 제안하는 PatchTST는 이러한 문제를 자연스럽게 극복할 수 있습니다. 그림 1에 나와 있듯이, 우리는 감독되는 설정과 동일한 Transformer 인코더를 사용합니다. 예측 헤드는 제거되고 D × P 선형 레이어가 추가됩니다. 패치가 겹치는 경우와는 달리, 각 입력 시퀀스를 정규적으로 겹치지 않는 패치로 나눕니다. 이것은 관측된 패치가 마스크된 패치의 정보를 포함하지 않도록 편의상입니다. 그런 다음 일부 패치 인덱스를 균일하게 무작위로 선택하고, 이러한 선택된 인덱스에 따라 패치를 제로 값으로 마스킹합니다. 모델은 MSE 손실로 마스킹된 패치를 재구성하기 위해 훈련됩니다. 우리는 각 시계열이 공유 가중치 메커니즘을 통해 상호 학습되는 고유한 잠재적 표현을 갖게 될 것이라고 강조합니다. 이 디자인은 사전 훈련 데이터가 하류 데이터와 시계열 수가 다를 수 있으며, 다른 접근 방식에서는 불가능할 수 있습니다. 1Zerveas et al. (2021)은 시계열 Transformer에서 BatchNorm이 LayerNorm보다 우수한 성능을 발휘함을 보여주었습니다.
정리하면,
- 패치로 입력을 분할: 입력 시계열을 패치로 분할하면 각 패치는 입력의 부분적인 표현을 나타냅니다. 이는 입력 시퀀스의 지역적인 특징에 집중하여 학습하도록 모델을 유도합니다. 이렇게 하면 전체 시퀀스를 모두 고려하지 않고도 모델이 유용한 정보를 학습할 수 있습니다.
- 무작위 마스킹: 일부 패치 인덱스를 무작위로 선택하여 해당 패치를 마스킹하는 것은 모델이 입력의 일부를 완전히 이해하는 대신, 일부 정보를 예측하도록 유도합니다. 이는 모델이 특정 패턴에 너무 많이 의존하지 않고 다양한 패턴을 학습할 수 있도록 도와줍니다.
- MSE 손실을 통한 훈련: PatchTST는 마스킹된 패치를 복원하는 데 사용되는 평균 제곱 오차(MSE) 손실을 최소화하는 방식으로 훈련됩니다. 이는 모델이 입력 시퀀스의 패턴을 재구성하도록 유도하며, 이는 과적합을 방지하고 일반화 성능을 향상시킬 수 있습니다.


attention map

이 결과를 통해 상관관계가 높은 데이터는 잘 학습한다는 것을 알 수 있고, 그렇지 않은 경우 학습 성능이 떨어진다는 것을 알 수 있다.
즉 외부 환경에 영향을 많이 받는 경우, 해당 모델은 사용하기 어렵다는 말일 수도 있다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] MASK R-CNN (0) | 2024.03.25 |
|---|---|
| [논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network (0) | 2024.03.20 |
| [논문 리뷰] Fast R-CNN (0) | 2024.03.19 |
| [논문 리뷰] Crossformer (0) | 2024.03.17 |
| [논문 리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2024.03.14 |