
티스토리 뷰
Crossformer : TRANSFORMER UTILIZING CROSS- DIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTING
논문을 리뷰할 것이다! 제목에서 transformer 내용인 것까진 알겠는데, cross dimension dependcy가 뭔지 의아해 했다. 논문을 읽으면서 알아보자.
0. abstract
cross dimension dependcy란 변수랑 변수 사이에 상관관계가 존재한다는 의미이다. 이는 다변수인 시게열 데이터셋에서 결과에 대한 예측이 어렵게 된다.
이를 보완한 것이 이 논문에서 제시한 crossformer이다.
간략한 구조
1. Multivariate Time Series(MTS)가 input으로 들어가면 Dimension-Segment-Wise (DSW) 을 통해 2D array로 변한다.
2. Two-Stage Attention (TSA) layer을 통햐 cross-time & cross-dimension dependency 특징 추출한다. 3. Hierarchical Encoder-Decoder (HED) 이 다른 크기의 시계열 예측에 쓰이면서 결과가 나온다.
1.Introduction
MTS는 각 변수가 하나의 차원을 나타낸다. MTS 예측은 날씨, 에너지, 금융 등 분야에서 잘 쓰인다. 0. abstract에서도 얘기했듯이, transformer 기반 모델이 MTS 중에서도 long-term temporal dependency에 대해서도 예측을 잘 하게끔 발전했다. 하지만, cross-time dependcy, 즉 변수 서로가 의존성을 지니는 문제는 예측 정확도에 치명적인 요인이다. 한 변수(한 차원)가 다른 차원에서 연관된 데이터인 경우 예측에 대한 정확도를 높일 수 있기 때문이다. 예를 들어, 미래 온도를 예측할 때, 과거의 기온들뿐만 아니라 과거의 바람 속도 및 풍향 또한 영향을 미칠 수도 있기 때문이다.
이전에는 latent feature를 추출하는 CNN, GNN을 이용해서 했지만, 최근에는 embedding을 이용한 transformer 기반 모델을 사용하여 이 cross 의존성을 활용했다. 모든 차원의 data points를 embedding하여 다른 시간대 step마다 feature extractor를 추출했다. 이 경우 cross-time dependcy는 잘 잡혔지만, cross-dimension dependcy의 특징을 잘 잡지는 못했다.
dimension을 잡기 위해 고안된 것이 Crossformer이다.
전체적인 구조는 abstract에 나온 것과 같으며, 세부적으로
1. DSW란, 각 차원의 series가 segment로 나뉘며, feature vector로 embedded된다. DSW embedding의 결과는 2D vector array를 지니는데, 각 축은 시간과 차원이다.
2. Two-stage dectector 는 cross-time 과 cross-dimension dependency를 2D vector array에서 잘 뽑는다.
3. Hierarchical Encoder-Decoder (HED) 이란 각 layer가 scale에 대응한다. Encoder’s upper layer가 인접한 결과 부분(adjacent segments output)와 합쳐지고, 이는 lower layer 를 조잡한 크기로(다소 범위가 큰) 잡으면서 dependcy가 정해진다. Decoder layers는 다른 크기의 예측과 이들을 합쳐서 최종 예측을 만들어 낸다.
이렇게 cross-dimension dependcy 정보도 이용하면서 time series forecasting의 정확도를 더 높일 수 있게 됐다.
2. related work
(1) Multivariate Time Series Forecasting.
MTS 예측에는 크게 두 가지, statiscal & neural model로 나뉜다.
VAR & VARMA 은 statiscal model로 쓰임. -> linear & cross dimensional & time dependcy 파악하기 좋음.
LSTnet에서 CNN &RNN을 결합했는데, CNN = cross dimensional / RNN = cross time dependcy를 해결하기 위함이다.
GNN = cross dimensional 해결하기 위해서 활용되기도 함. ex. MTGNN
(2) Transformers for MTS Forecasting
transformer 활용하여 MTS forecasting 해결하려는 노력이 있었다.
Logtrans->LogSparse 발전을 통해 O(L^2) to O(L(log L)^2)로 복잡성을 줄였다.
Informer, autoformer, FEDformer, preformer 들이 MTS forecasting으로 제시되었었다.
(3)Vision Transformers.
ViT로 transformer한 것을 시각적으로 제시하고자 한 모델이다. ViT는 이미지를 non-overlapping medium sized patcher로 쪼갠 후 다시 재정렬해서 Transformer의 input이 되게끔 조정한다. 이는 이 저자의 crossforemr의 DSW embedding에 영감을 주게 되었다.
3. 방법(methodology)
3.1 Dimension Segment Wise Embedding
앞서 제시된 transformer가 cross time dependcy는 잘 추출했다고 했는데, 이는 무슨 과정으로 나오는지 알아보도록 하자.
(1) 각 정해진 time step(전체 t을 각각 T만큼 끊어서)마다 안에 있는 data point->vector로 전환. (x_t -> h_t) 이렇게 time step마다 잘라서 forecasting 비교로 cross time dependcy에서는 특징을 잘 추출할 수 있었다.
(2) MTS에서 하나의 step만으로는 유의미힌 예측이 불가능하다. 또한, 한 time step에서 이전과의 연관성이 크기 마련인데, 이는 다음 사진에서도 볼 수 있듯이 인접한 time step의 data point끼리 유사한 attention score를 가짐을 알 수 있다.
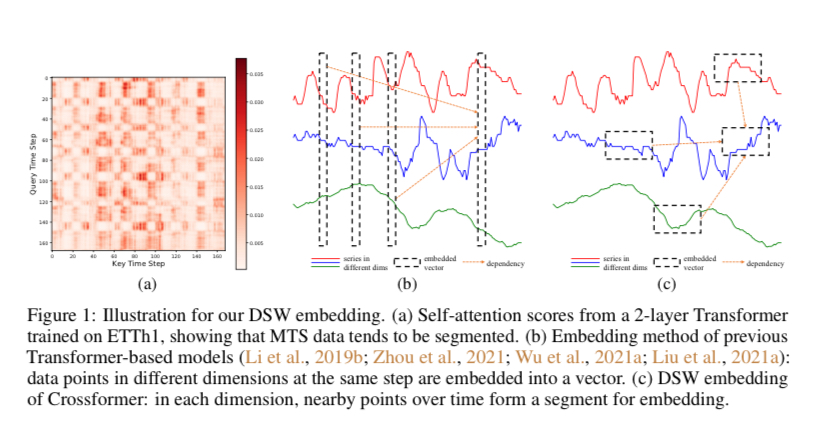
이로써 embedded vector는 각 step마다의 모든 차원을 대변해주는 것보다는 single dimension을 대표해주는 series가 되어야 한다. 그래서 DSW를 제시해서 각 차원마다 일정 길이 \(L_{seg}\)만큼으로 나누고, 이를 다음과 같은 embedding vector로 바꾼다.
\(x_{i,d}^s \in R^{L_{seg}}\)이다.
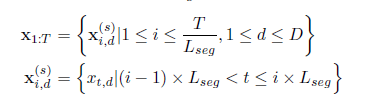
그리고 각 segment는 linear projection(정사영)을 통해 다음과 같은 position embedding을 가진다.
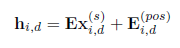
E는 입력 데이터를 저차원 공간에서 고차원 공간으로 변환하는 함수(learnable projection)이다. \(E_{i,d}^{pos} \in R^{d_{model}}\)은 시퀀스의 각 위치에 대한 학습 가능한 위치 임베딩이다. 이러한 embedding을 거치면, 다음과 같은 2D vector array가 만들어진다.

3.2 Two-Stage Attention Layer
그냥 segment 자른 거를 바로 transformer에 넣을 수 있는데, TSA를 넣어줌으로써 그렇지 않게 한 이유는 두 가지가 있다.
1) image의 높이와 너비가 서로 바뀔 수 없는 경우처럼, MTS의 time, dimension이 서로 바뀔 수가 없는 경우 각각 차원은 의미를 가지며 다르게 다뤄야 한다.
2) 그대로 넣으면 복잡성이 강해짐.
TSA를 사용함으로써 cross time & dependcy의 특성을 잡을 수 있게 된다. 다음은 TSA의 구조이다.
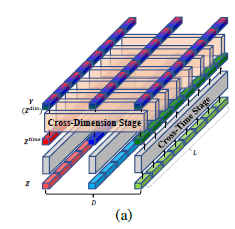

(1) Cross-Time Stage
2D array \(Z \in R^{L \times D \times d_{model}}\)라고 가정하자. Z는 DSW의 embedding 또는 저차원 TSA 층을 지난 결과라고 하자. 이 vector에 multi-head self attention(MSA)를 곱한다.

Layer Norm은 각 층을 정규화시킨 것이다. MLP = Multi-layer feedforward network(그냥 선형 함수라고 생각하면 된다.)
이 식의 복잡성은

이다. 이 stage를 통과하면, time segement들의 dependcy는 \(Z^{time}\)으로 변한다. 또한, 결과는 cross-dimension stage의 input이 된다.
(2) Cross-Dimension Stage
DSW 처럼 time step마다 자르고, 큰 차원 D 자체에 바로 MSA를 씌울 수는 없기에, router mechanism을 적용시켰다.
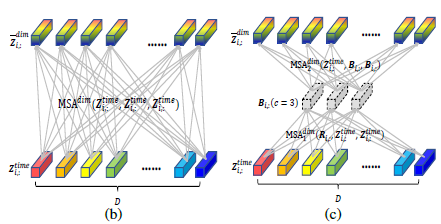

small fixed number c ( c<<D) 를 설정하고, time step i 를 router(특정 시간 단계에서의 각 차원에 대한 학습 가능한 벡터)를 가리킨다. 이 벡터들은 먼저 다차원 자료의 각 차원에서의 메세지를 집계한다. 또한, 집계 과정에서, 이러한 라우터 벡터들은 "MSA(Multi-Head Self-Attention)"에서 쿼리(query)로 사용됩니다. MSA는 Transformer 아키텍처에서 사용되는 자기 주의 메커니즘이며, 입력 벡터를 자기 자신과 비교하여 각 벡터의 중요도를 계산하는 데 사용됩니다. 여기서는 라우터 벡터들이 이 비교 과정에서 쿼리로 사용되는 것이다. 이러한 비교 과정에서, 다차원 자료의 각 차원에 대한 벡터들은 키(key)와 값(value)으로 사용됩니다. 즉, 라우터 벡터들은 다른 차원의 정보를 집계하고 각 차원에 대한 중요도를 계산하는 데 사용됩니다. 그 이후, 각 차원의 vector는 계산된 중요도에 따라 집계된 메세지를 기반으로 해당 차원에 메세지를 분배하는 역할이다.

\(R\)은 learnable vector array 이고, \(B\)는 모든 차원의 메세지 집합체, 그리고 \( \bar{Z}^{dim}\)은 router mechanism의 output이다.
(1)과 (2)의 과정을 거치면 다음과 같은 식이 나온다.
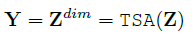
\(Z\)는 TSA layer의 input vector이다. 이로써 cross time and dimension dependcy가 Y에 잡히게 된다.
3.3 Hierarchical Encoder - Decoder
다른 scale(크기)의 MTS 예측에서 정보를 뽑기 위해 HED가 쓰인다.
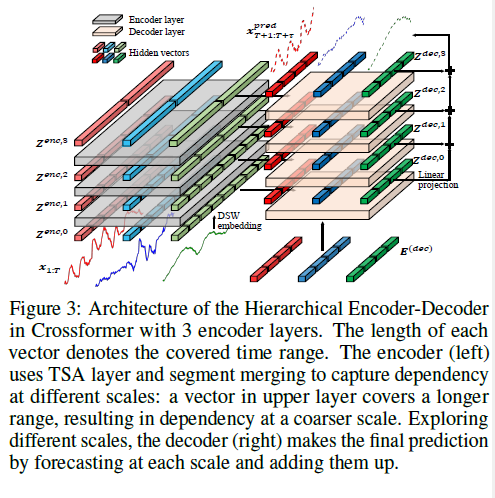
DSW embedding, TSA 층 그리고 segment를 결합하여 HED를 생성한다. 위의 layer은 예측을 위해 더 거시적인 규모의 정보를 활용한다. 예측값은 마지막 결과로 결과로 붙여진다.
(1) Encoder
각 time domain의 인접한 두 개의 벡터마다 거시적인(coarser) level에서 표현을 얻기 위해 합쳐진다. 그 다음에 TSA layer가 이 scale에서 특징을 잡아낼 수 있게 한다. 이 과정은 다음 식으로 나타내며, 관련 수식은 두 번째 사진과 같다.

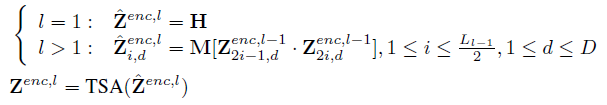
H는 DSW embedding의 2D array, \(Z^{enc, l}\)는 l 번째 encoder layer의 output이다. M은 segment merging의 learnable matrix이다. L은 층 l-1에서의 각 차원의 segment 수이다.
(2) Decoder
decoder에서 N+1 layers이 쓰인다.

위의 사진과 같은 구조를 가진다. MSA에 넣는 변수들은 encoder 과 decoder 사이를 이어주는 key, value 값이다. MSA 결과(다음 첫 번째 사진)는 skip connection과 MLP의 output이다.

그리고 다음 변수들은 decoder의 output을 의미한다.
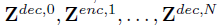
Linear Projection(정사영)은 각 layer의 output 후에 적용되며, 각 층의 예측값을 뽑아낸다. 다음 식에 의해서 산출된다.
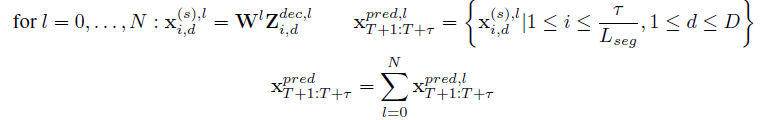
4. Experiments
Dataset
6개의 world dataset을 쓰며, 1) ETTh1, 2), ETTm1, 3) WTH, 4)ECL, 5) ILI, 6)Traffic을 썼다.
Baselines
1) LSTMa, 2) LSTnet, 3) MTGNN, 4) Transformer, 5) Informer, 6)Autoformer, 7)Pyraformer, 8)FEDformer 가 쓰인다.
Setup
train/val/test sets를 쓰였으며, 각 dataset마다 future window size \(\tau\)를 바꿔가면서 성능을 높였다. MSE & MAE 가 평가 지표로 사용됨. crossformer는 다른 model은 한 날의 time에 여러 corvariates를 추가하여 과거 series를 변화시키기도 했지만, 과거 series를 미래를 예측하는 데에만 쓰였다.
보다시피 결과는 잘 나왔다.
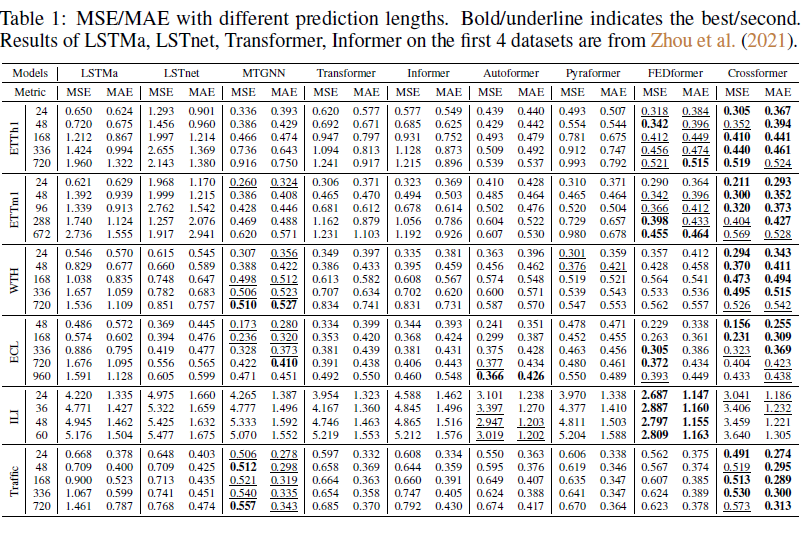
Crossformer가 모든 dataset에 대해서는 가장 최우선의 성능을 보인 것은 아니다. 최종적인 DSW+TSA+HED를 결합한 모델 말고도 일부만을 결합했을 때의 성능 차이를 비교했지만, 이 전부를 모두 결합한 것이 결과가 가장 잘 나왔다.
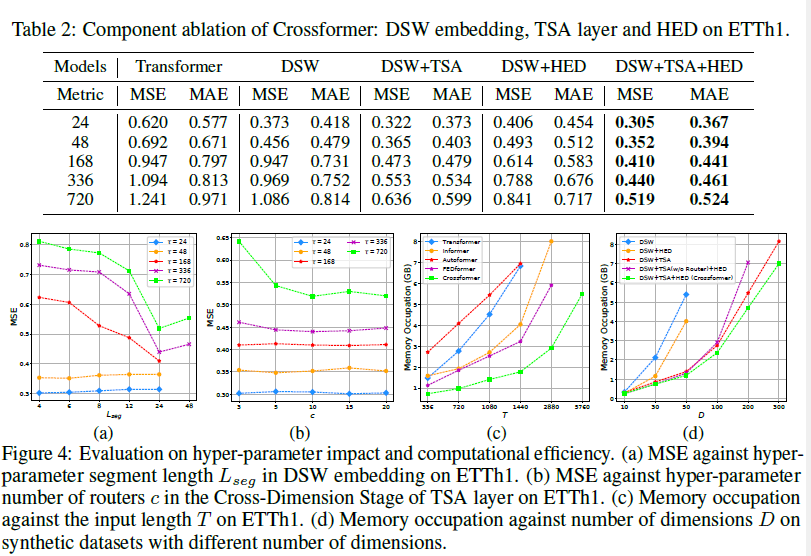
또한, 실험을 진행하다보니, 1) long-term forecasting(\(\tau\)가 클 때)에서 segment를 늘리면, MSE 감소. 2) TSA layer에서 number of Router(= c)의 값은 10이 적당했다. 또한, 연산량 측면에서도 다음 사진을 보면 효율적을 진행됨을 알 수 있다.

한계
1) Cross-Dimension stage에서 simple full connection을 진행했는데, 이는 고차원 dataset에서 noise를 일으킬 수 있다.
2) MTS 예측에 transformer가 정말 효율적인 것이냐, DLinear 가 여러 transformer 종류들을 outperform 한다. 이 이유는 transformer의 MSA가 permutation-invariant하기 때문이다. 그러므로 transformer의 ordering preserving capability를 증가시키는 것이 중요하다.
3) MTS 분석에서 dataset은 작고, 간단하다. 좀 큰 dataset에서는 잘 효과가 안 나올 수 있다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] MASK R-CNN (0) | 2024.03.25 |
|---|---|
| [논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network (0) | 2024.03.20 |
| [논문 리뷰] Fast R-CNN (0) | 2024.03.19 |
| [논문 리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation (0) | 2024.03.14 |
| [논문 리뷰] A TIME SERIES IS WORTH 64 WORDS:LONG-TERM FORECASTING WITH TRANSFORMERS (0) | 2024.03.12 |