티스토리 뷰
[논문 리뷰]ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
hyuna_engineer 2024. 5. 7. 02:49ConvNeXt 발전 형태이다.
ConvNet 논문( Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In CVPR, 2022) 리뷰는 다음에 진행할 것이다.
현재 이 모델을 이용한 프로젝트 준비 중이기에 이 논문 먼저 리뷰해볼 것이다.
Abstract
MAE와 같은 self-supervised learning을 통해 a fully convolutional masked autoencoder framework 과 a new Global Response Normalization (GRN)을 ConvNeXt 구조(ConvNet 발전시킨 모델) 결합하여 이를 통칭하여 ConvNeXt v2라고 이름을 붙인 것이다.
Introduction
visual representation learning system 은
1. 어떤 신경망이 선택되었는가
2. 네트워크 훈련이 어떻게 진행되었는가
3. training data가 어떤 것이 쓰였는가
에 따라 성능이 결정된다. (어찌보면 당연한 것..)
그래서 특히 어떤 신경망 구조를 가지느냐 이것이 큰 요인을 가지기에 구조 구성이 정말 중요해졌다.
ConvNeXt v2라서 verison 1은 어디 있냐 하면 traditional convNet을 변형한 제가 서두에 언급한 2022년 논문이 version 1이다. 이 내용은 위의 블로그 포스트를 참고 바란다. 이러한 conv 발전 모델들은 ImagNet의 supervised learning을 벤치마킹하여 발전된 것들이다.
바로 이런 vision representation learning이 supervised learning 에서 self-supervised로 발전한 것.
또한 MAE=masked autoencoder는 maksed language model에서 큰 성과를 거두면서 발전된 모델인데 이를 vision에도 활용하면서 좋은 결과를 보인 것이다.
그래서 어떻게 masked autoencoder를 ConvNeXt와 엮나 싶을 것이다.
1. MAE = encode-decoder 으로 구성되고, transformer기반의 연속적 처리 능력에 최적화된 모델이다. Sliding window를 쓰는 CNN 기반 ConvNets에 상호호환되기에는 부적합할 수 있다.
MAE: 전체 데이터를 볼 수 있도록 설계되어 있어, 마스킹된 부분도 전체 데이터의 컨텍스트를 통해 이해하고 복원한다. 이는 전체적인 데이터 구조를 이해하는 데 중점을 둔다.
Sliding window: 각 창(window)을 독립적으로 보고, 각각의 작은 창에 대한 정보만을 이용하여 특성을 추출한다. 이는 매우 지역적인 정보에 집중하는 방식인 것이다.
2. 이러한 구조 상의 차이로 둘의 훈련 목적지가 다르게 설정될 수 있다.
이를 극복하고자 두 방식을 결합한 구조는 다음과 같다.
- masked input을 여러 patch들의 결합으로 보고, 안 가려진 부분이 대해서 sparse convolution 진행.
- transformer decoder를 single ConvNeXt block로 교체.
->ConvNeXt 모델을 마스킹된 입력으로 직접 훈련할 때 MLP(다층 퍼셉트론) 계층에서 특성 붕괴(feature collapse)라는 문제가 발생할 수 있다. 특성 붕괴란 모델이 특성의 다양성을 잃어버려 유사한 출력만을 내는 현상이다. 해결 방안으로 글로벌 반응 정규화(Global Response Normalization) 계층을 추가.
이렇게 transformer 결합해도 original보다 성능 좋다.
Architecture
1) Fully Convolutional Masked Autoencoder

decoder를 single ConvNeXt block으로 교체했다고 했다. 이렇게 되면서 fully connected가 된다.
1-1) Masking
Masking ratio 가 0.6이 되게 하고, raw input이 들어오면 랜덤하게 0.6만큼 convolutional로 downsample 되면서 mask를 씌우고, 이후 upsample로 높은 해상도까지 올린다. 여기서는 32x32 input이며, augmentation은 crop밖에 적용 안 함.
2) Encoder Design
masked image modeling 을 잘 만들기 위해서는 model이 masked region에서 단순히 copy & paste 한 것을 가져와서 다른 곳에다 붙이는 (야비한(?)) 방법을 멀리하도록 해야 한다. Transformer-based models에서는 visible patches를 encoder의 유일한 input으로 함으로써 방지할 수 있다. ConvNets에서는 2D image structure의 구조를 유지한 채로 patching을 진행해야함으로 어려움이 있다. 입력 단계에서 학습 가능한 masked token을 도입하는 것이 기존의 간단한 해결책이지만, 이러한 방식이 사전 훈련의 효율성을 감소시키며, 테스트 시점에서 masked token이 없고 이를 보고 전체를 예측해야 하므로 훈련 시와 테스트 시의 일관성 문제를 일으킨다.
이를 해결한 것
Masked image를 “sparse data perspective” 관점으로 바라보는 것이다. 즉, Masked image를 2D sparse array of pixels로 보는 것이다. Encoder의 기본적인 convolution layer를 submanifold sparse convolution으로 바꾸는데, 이는 visible data points에 대해서만 작업을 수행한다.
Submanifold sparse Convolution이란?
3D data에 적합한, 위에서 말했다시피 visible data point에 대해서만 연산을 진행한다. 방법은 다음과 같다.
활성 위치 추적: 일반적으로 특정 조건(예: 0이 아닌 값)을 만족하는 데이터 포인트, visible data point라고 정의.
자료구조: 효과적인 활성 위치 관리를 위해 해시 테이블, 좌표 리스트, 옥트리(OcTree), k-d 트리 같은 자료구조를 사용할 수 있다. 공간을 효율적으로 사용하면서도 빠른 검색과 업데이트를 가능하게 한다.
Convolutional Mask 적용: 일단 활성 위치가 결정되면, 각 활성 위치 주변의 이웃만을 대상으로 Convolutional Mask(필터)를 적용합니다. 비어 있는 공간은 연산에서 제외되기 때문에 계산 효율이 크게 향상됩니다.
Skip-Connection: 데이터의 희소성을 유지하기 위해, 비어 있지 않은 위치들만을 포함하는 새로운 특징 맵을 생성하고, 이를 다음 레이어로 전달한다. 필요에 따라 활성 위치 주변을 확장하거나, 새로운 활성 위치를 추가하는 방식으로 연산이 진행된다.
Fine-tuning 단계에서 sparse convolution layers 를 standard convolution를 바꿔서 진행할 수 있다. 또 다른 대안은 binary masking operation을 조밀한 convolution operation과정에서 적용할 수 있다.
3) Decoder Design
우선 Plain ConvNeXt block를 decoder로 썼다. 다른 복잡한 decoder 안 쓴 이유는 가장 평범한 저 블록이 가장 정확성이 높았기 때문이다. Dimension of the decoder 은 512으로 결정했다.
4) Reconstruction target
Mean squared error (MSE)로 평가 지표 사용. reconstructed and target images 사이의 비교.
이들을 섞어서 촤종적으로 FCMAE (Fully Convolutional Masked AutoEncoder (FCMAE))모델 완성.
ConvNeXt-Base model를 encoder로 쓴다. 전이 학습(= 한 분야에서 학습된 모델을 다른 분야에 적응하는 학습 방법) 을 위해 end-to-end fine-tuning 을 진행한다. Sparse convolution 적용한 것이 안 적용한 겻보다 정확성이 높다.

self-supervised을 supervised learning과 비교해서 진행.

사진 보면, supervised 300 epoch이 FCMAE보다 정확성이 높다.
Global Response Normalization
FCMAE를 pre-training을 더 효율적으로 하기 위함. 이는 ConvNeXt 구조와 결합.
Feature collapse
FCMAE로 사전 훈련된 ConvNeXt-Base 모델의 활성화를 시각화해보니 흥미로운 '특성 붕괴(feature collapse)' 현상이 관찰되었습니다. 많은 특성 맵들이 비활성화되거나 포화 상태이며, 채널 간에 활성화가 중복되고 있다. "특성 붕괴"는 모델의 특성 맵들이 제대로 작동하지 않거나, 모든 입력에 대해 거의 같은 값을 출력하여 유용한 정보를 제공하지 못하는 현상을 의미한다.
Feature cosine distance analysis

관찰 결과를 정량적으로 검증하기 위해 feature 코사인 거리 분석을 수행했다. \(X \in \mathb{R}^{H \times W \times C}\)가 주어지면, \(X_i \in R^{H \times W}\)은 ith channel의 feature map이고, HW dimensional vector로 reshape하고, 채널 전체의 평균 쌍별 코사인 거리는 위의 사진처럼 거리를 계산한다. 거리 값이 높을수록 feature가 더 다양하며, 값이 낮으면 feature 사이에 중복이 일어난다.
이 분석을 수행하기 위해 ImageNet-1K validation set의 다양한 클래스에서 1,000개의 이미지를 무작위로 선택하고 FCMAE 모델, ConvNeXt supervised 모델, MAE로 사전 학습된 ViT 모델을 포함한 다양한 모델의 각 레이어에서 고차원 feature를 추출하였다. 그런 다음 각 이미지의 레이어당 거리를 계산하고 모든 이미지의 값을 평균화하였다.
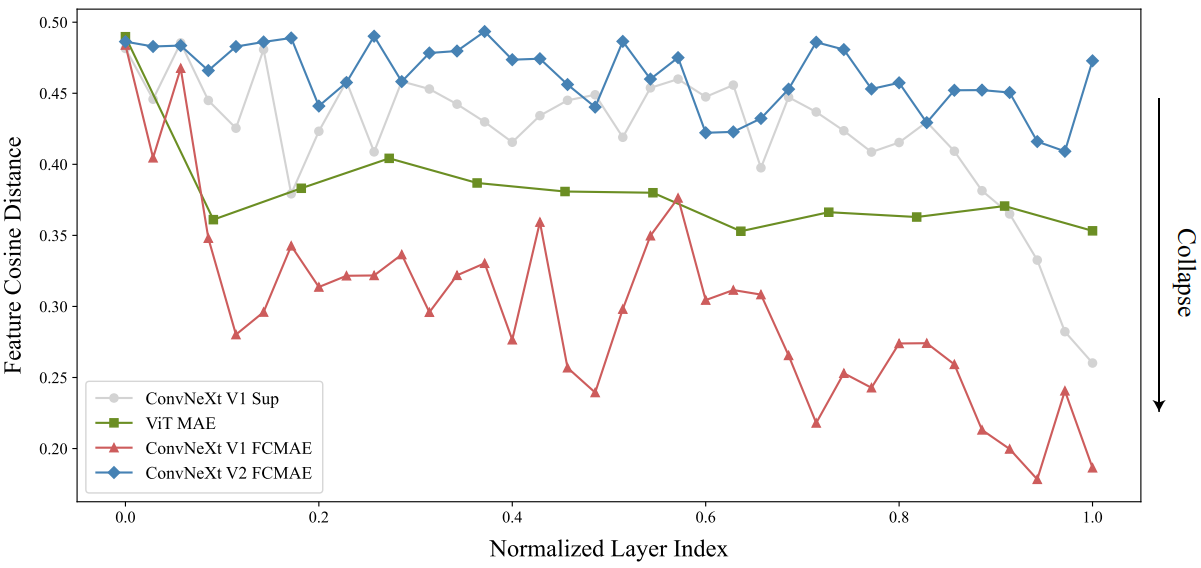
위는 결과.
Approach
이 연구에서는 뇌에서 발견되는 다양한 메커니즘들이 뉴런의 다양성을 촉진한다는 점에 주목한다. 특히, 측면 억제는 뉴런의 반응을 더 선명하게 하고, 뉴런 각각의 반응을 뚜렷하게 대비시켜주며 선택성을 향상시키는 역할을 한다. 이러한 효과는 전체 뉴런 집단의 반응 다양성을 증가시키는 데에도 기여한다. 딥러닝 분야에서는 비슷한 원리의 측면 억제 기능이 반응 정규화를 통해 적용될 수 있다. 이에 따라, 입력 특성 𝑋∈𝑅^(𝐻×𝑊×𝐶)를 처리하기 위해, global response normalization (GRN)이라는 새로운 응답 정규화 레이어를 제안한다.
1. Global feature aggregation
2. Feature normalization
3. Feature calibration
1. 글로벌 함수를 이용하여 공간 feature map \(X_i\)를 벡터 gx로 집계->pooling layer로 생각하면 됨.

L2-norm을 사용한 것이 성능이 좋다. 밑의 식이 그렇나 것을 반영한 식이다.

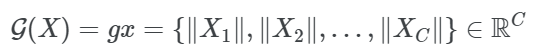
2. 바로 위 식 글로벌 함수에 정규화 함수 다음 식을 적용(=표준 분할 정규화)

이 식을 다른 모든 채널과 비교하여 상대적 중요성을 계산한다.
3. 원래 입력에 대한 정규화까지 한 것에 보정값 적용.
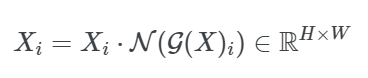
최적화를 쉽게 하기 위해 두 개의 추가 학습 가능한 파라미터 r, B를 추가하며, 0으로 초기화한다. 최종 GRN 결과는

이다.
ConvNeXt v2
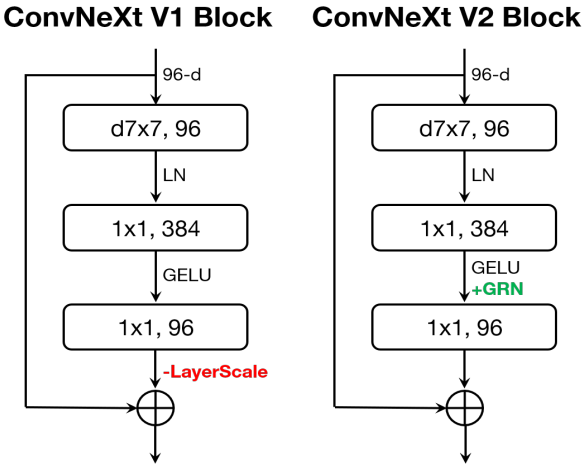
GRN을 적용하게 되면 layer scale이 필요 없고, 제거 가능하다.
GRN의 영향
시각화 & 코사인 거리 분석으로 GRN을 장착하면 FCMAE로 사전 학습된 모델이 300 epoch supvervised baseline보다 더 뛰어난 성능을 보인다.
Feature 정규화 방법

GRN이 훨씬 더 좋은 성능을 가진다.
Feature gating 방법과의 관계
동적 feature gating 방법을 사용하며, 어떤 것이 더 효율적인지 비교한다.

pre-training & GRN 역할

결과

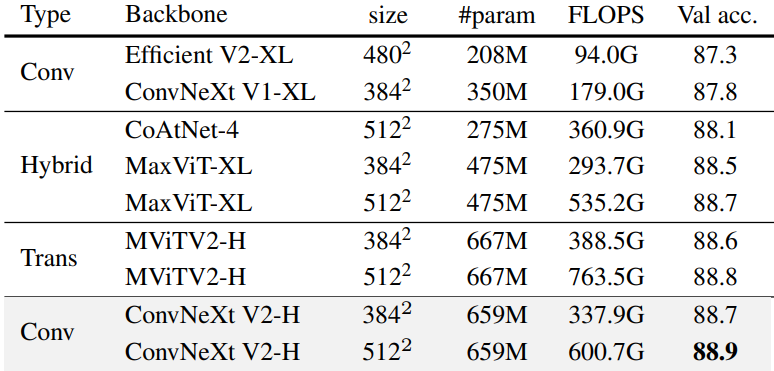
training은 다음과 같이 진행
- FCMAE 사전 학습
- ImageNet-22K fine-tuning
- ImageNet-1K fine-tuning
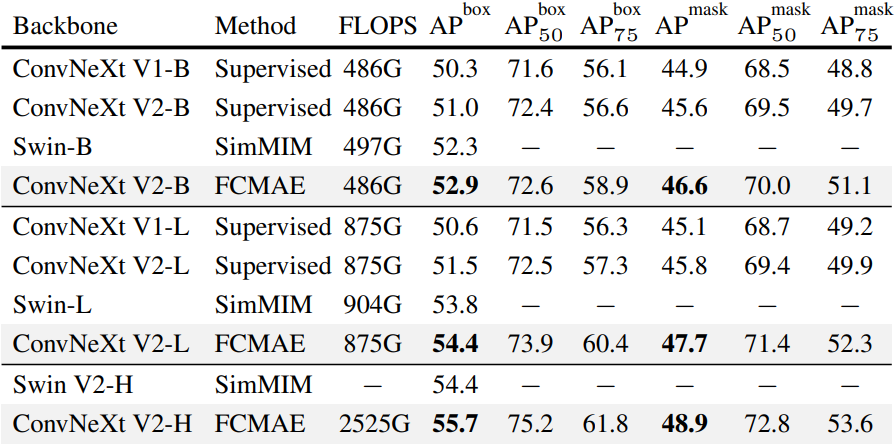
Transfer Learning
Mask-RCNN을 사용한 COCO object detection 및 instance segmentation 결과