
티스토리 뷰
[논문 리뷰] TIME-LLM: TIME SERIES FORECASTINGBY REPROGRAMMING LARGE LANGUAGE MODELS
hyuna_engineer 2024. 3. 31. 02:05Abstract
time sereis forecasting은 다른 분야와 다르게 고유의 task와 응용이 요구되는 사안이 많다. Data sparsity(데이터 분포도)가 주요 이유로 꼽힌다. 최근 연구에서는 LLM이 pattern 인식과 token들의 sequence 인식을 잘 할 수 있다는 연구가 나왔다. 이를 고려하여 TIME-LLM을 제시했다. LLM을 변형시킨 것으로, 일반적 time series forecasting에 사용되며, backbone LM은 그대로 유지한 채 구조를 재구성한 것이다. LLM에 처음 input으로 넣기 전에 input time series을 가공해서 집어 넣도록 했다. LLM 특성상 prompting이 정말 중요하기 때문이다. 이 augmentation에 Prompt-as-Prefix (PaP)를 제시했는데, 이는 input context 변형과 input patches에 대해 reprogrammed 시켰다. 기존 SOTA(state-of-the-art)보다 좋은 성능을 냈고, TIME-LLM은 few-shot, zero-shot에서도 좋은 성능을 보였다.
1. Introduction
Generalizability
일반성을 높이기 위해 LLM을 활용이 대두되었다. LLM은 few shot, zero-shot에 좋은 성능을 보여줬기 때문에 일반화 또한 좋은 결과를 얻을 것이라고 예측했다. 요즘 LLM 모델은 각 scratch마다 번거롭게 계산 안해도 generalization이 가능하게 해주었다.
Data Efficiency
LLM은 few shot, zero shot에 특화된 것처럼 일부 example만 학습해도 결과를 잘 낼 수 있다. time series 같은 경우 예를 들어 historical data가 좋은 성능을 낼 수 있는 그러한 경우이다.
Reasoning
LLM은 생성 능력이 좋은 편이다. 정교한 추론 능력과 pattern 인식 능력이 있기 때문인데, 이를 억제해야지 time forecasting에 높은 정확도를 보여주며, high level concept을 활용할 수 있게 도와준다.
Multimodal knowledge
LLM 구조랑 training 기술이 증가하면서, 이 모델은 점점 modaltites가 늘어났다. vision, speech, text 이런 쪽에도 특화되었다. 이렇게 능력이 증가하면 다양한 data type의 time sereis에도 좋은 예측성을 보이게 된다.
Easy Optimization
LLM이 거대한 computing을 한 번 학습하고, scratch 없이 바로 예측하게끔 요구될 수 있다. 현존하는 Forecasting model을 optimize하는 것은 특정 구조와 하이퍼파리마터 튜닝을 요구할 수 있다.
요약하면 LLM의 이러한 특성은 time series 예측에 좋을 수 있다고 저자는 주장한다.
하지만 그래도 단점은 존재한다. LLM이 discrete(단어를 토큰별로)한 것에 특화되지만, time series는 continuous data 이므로 특화되지는 않는다. 또한, time series 예측 능력은 LLM은 특화되어 있지 않다.
TIME-LLM은 framework를 다시 짜서 LLM이 time series에 특화되도록 바꾸었다. 다음 특징 두 개가 있다.
- time series를 "reprogram"하는 것이 가장 중요한 특징이다. times series data을 textprototype representation으로 reprogram했다. pre-trained된 backbone model 또한 바꾸지 않았다.
- Abstract에서 얘기 했듯이 "Prompt-as-Prefix(PaP)" 또한 도입했다. time series에 추가적인 문구(text 소개)를 붙여 넣는 prompt design을 한다.
2. Related Work
Task-Specific Learning

위의 사진은 각 Model 어떤 식으로 작동하는지 알려준다.
ARIMA model - 다양한 변수에 대한 time forecasting
LSTM - sequence modeling & 일부 convolutional network 첨가
Transformer - longer temporal dependcy에도 능숙하게 대처해줌
--> 다양한 시계열 데이터에 대해 유연하게 적용되거나 일반화될 수 있는 능력이 부족함.
In-Modality Adaptiontime series data에 supervised 또는 self-supervised learning을 적용했다. 이렇게 하면, similar domain에서 fine-tuned가 잘 되며, input time series를 잘 배울 수 있게 된다.
Cross-Modality AdaptionVoice2Series는 acoustic model(AM)을 적용했는데 speech recognition ->time series 분류까지 해주는 작업이다. 이는 time series를 AM에 맞게 변화시켰는데, 이는 multimodal fine-tuning으로 한계가 있다. 이거 말고도 LLM4TS가 있는데 이 또한 two-stage fine-tuning을 거치고, task-specific fine-tuning 또한 거친다. 다른 기저 모델은 바꾸지 않고, 이 정돔나 거쳤는데도, 다양한 time 분석과 SOTA 모델보다 좋은 성능을 보여주었다.
3. Methodology
모델의 아키텍쳐는 다음과 같다.
Llama & GPT-2와 같은 embedding-visible language foundation model을 backbone fine-tuning 없이 reprogramming 시킨 것이다.
historical observation sequence를
저자는 다음 모델이 다음 구성 요소 3가지로 이루어져 있다고 하자.
(1) Input Transformation
(2) Pre-trained & frozen LLM
(3) Output Projection
처음에 종속 변수가 여러 개인 다변량 time series 데이터를 N개의 종속 변수가 한 개인, 결과가 한 개인 데이터로 나눈다. 일종의 projection을 진행한다고 보면 된다. 그래서 이를
이후, 이 패치들을 대규모 언어 모델(LLM)에 입력으로 제공하고, 특정 프롬프트와 함께 사용하여 모델의 시계열 데이터에 대한 추론 능력을 향상시킵니다. 이 결과로 추출된 feature를
3.1 Model Structure
Input Embedding
각 input channel

S=stride. 이렇게 patch로 나눈 이유는 다음과 같다.(1) local information을 patch로 담으면서 local sematic information을 담는다. (2) tokenization을 진행하며 이는 input tokens를 함축적인 sequence로 형성하게 되는 것이다. 이는 computating 감소이런 patch는 다음과 같은 과정을 거친다.
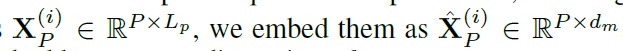
이렇게 embedded 되고,
Patch Reprogramming
모델이 다양한 데이터에 대해서도 추출할 수 있게 embedding된 sequence를 source data representation space로 배열할 때 noise를 추가한다. 시계열 데이터는 직접 편집하거나 자연어로 정보 손실 없이는 설명될 수 없으며, 이는 비용을 많이 소모하는 세밀한 조정 없이 대규모 언어 모델(LLM)을 직접 활용하여 시계열 데이터를 이해하도록 만들어야 하는데, 이는 쉽지 않다.

이런 embedding한
이를 실현하기 위해 multi-head attention을 도입했다. 식은 다음과 같다.

Prompt-as-Prefix
가장 중요한 건 prompt design 넣을 때 time series data에 instruction, 즉 주석 같은 걸 달았다. 다음 사진처럼 진행했다.

Patch-as-Prefix에서, 언어 모델은 시계열에서 이후의 값을 예측하도록 프롬프트됩니다. 이는 자연어로 표현되는데, 두 가지 한계점이 있다.
(1) 언어 모델은 일반적으로 외부 도구의 도움 없이 고정밀 숫자를 처리할 때 감도가 떨어지며, 이는 장기적인 시간 예측을 정확하게 수행하는 데 있어 상당한 어려움을 제시한다.
(2) 언어 모델이 숫자를 다루는 방식의 일관성 부족하다. 언어 모델이 숫자를 다양한 형태로 표현할 수 있어, 같은 숫자를 나타내는데도 표현 방식이 달라질 수 있다. 예를 들어, 소수점 숫자 0.61을 표현하는 데 ‘0’, ‘.’, ‘6’, ‘1’ 또는 ‘0’, ‘.’, ‘61’과 같이 다른 방식을 사용할 수 있습니다. 이는 후처리 과정에서 추가적인 조정이 필요함을 의미한다.
TIME - LLM은 다음과 같은 방법으로 제약을 이겨낸다.
- 데이터셋 맥락(dataset context): 데이터셋 맥락은 대규모 언어 모델(LLM)에 입력 시계열 데이터에 관한 필수적인 배경 정보를 주도록 한다. 시계열 데이터는 다양한 분야에서 각기 다른 특징을 보이는 것을 이용해서 모델이 입력 데이터의 특성을 이해하는 데 도움을 주도록 한다.
- 작업 지시(task instruction): 작업 지시는 특정 작업을 위한 패치 임베딩의 변환을 안내하는 데 있어 LLM에게 중요한 역할을 한다. 이는 모델이 수행해야 할 작업의 성격을 명확하게 이해할 수 있도록 돕는다.
- 입력 통계(input statistics): 입력 시계열 데이터에는 추세와 지연(lags)과 같은 추가적인 중요 통계 정보를 포함시켜 패턴 인식과 추론을 촉진한다. 이는 모델이 데이터의 중요한 특성과 패턴을 더 잘 인식하고 이해할 수 있게 한다.
Output projection도 진행한다.
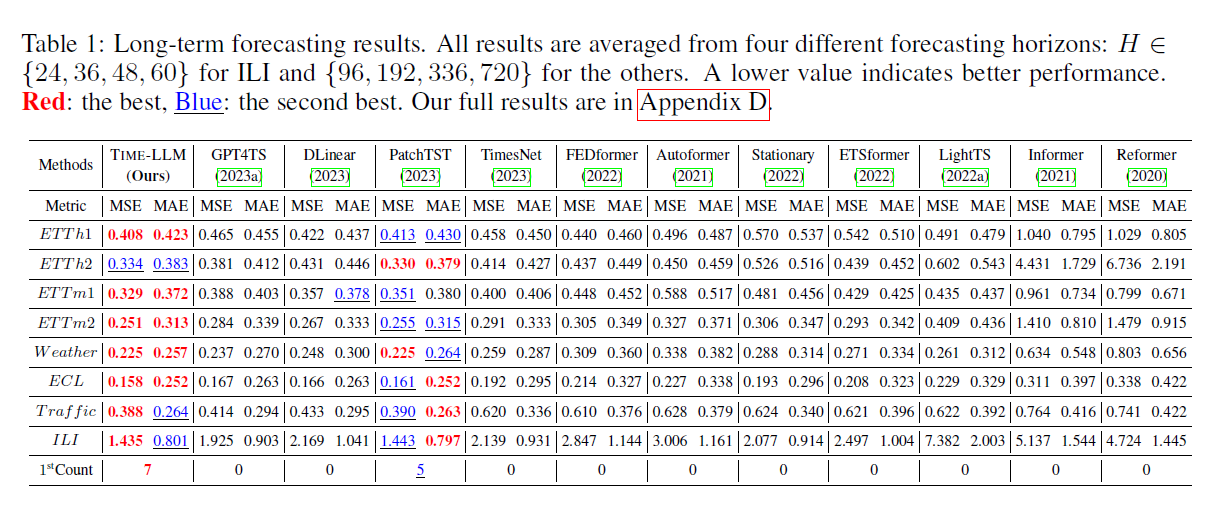
4.Main Results
SOTA 모델인 PatchTST (2023), ESTformer (2022), Non-Stationary Transformer (2022), FEDformer (2022), Autoformer
(2021), Informer (2021), Reformer (2020).//competitive models, including GPT4TS (2023a), LLMTime (2023), DLinear (2023), TimesNet (2023), LightTS (2022a)와 비교를 진행했다.
4.1 Long-term, 긴 시간 예측
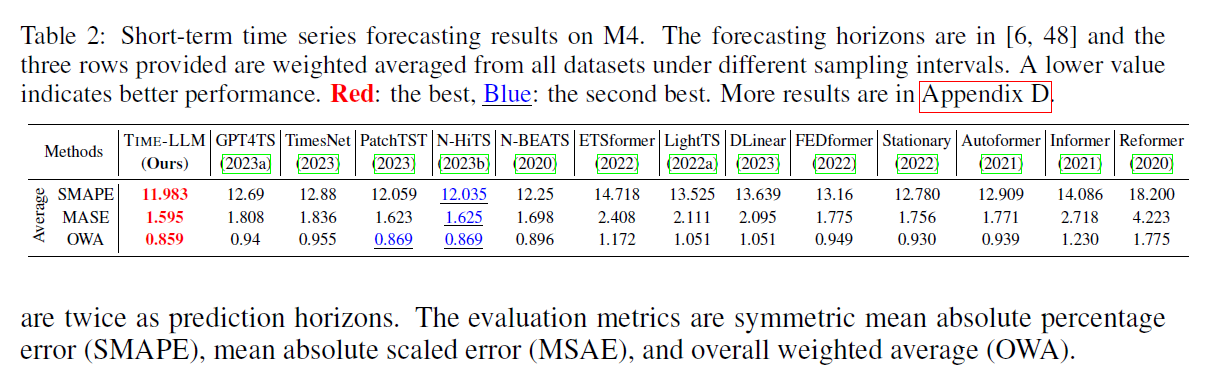
4.2 short-term, 짧은 시간 예측
4.3 Few-shot Forecasting
few - shot : training data의 10%, 5%만을 학습시킴.


4.4 Zero-shot Forecasting

4.5 Model 분석
Language Model Variants
backbone 2개를 다양한 경우의 수로 바꿔 가면서 비교했다.

Cross-modality Alignment
패치 재프로그래밍, Prompt-as-Prefix 접근법, 그리고 입력 통계를 포함하는 것이 시계열 데이터를 효과적으로 예측하기 위해 LLM을 재프로그래밍하는 데에 중요하다는 것을 성능 차이로 보여줬습니다. 이러한 요소들을 제거하면 LLM의 성능이 현저하게 감소함을 보여줍니다.
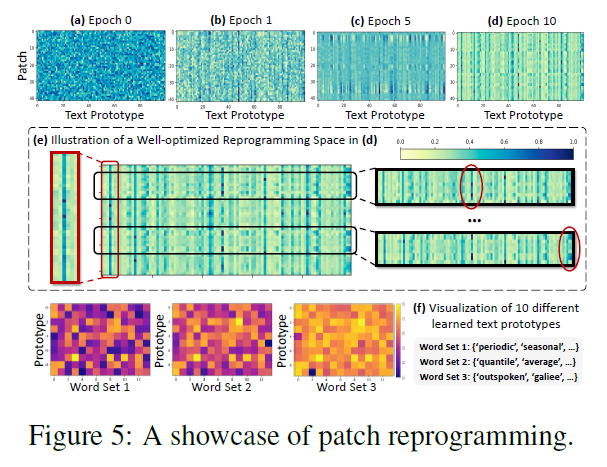
Fig. 5에서 ETTh1에 대한 결과를 보여주며, 100개의 텍스트 프로토타입을 사용하여 48개의 시계열 패치를 재프로그래밍하는 과정을 보여준다. 상위 4개의 서브플롯은 무작위로 초기화된 (a) 상태에서 잘 최적화된 (d) 상태로의 재프로그래밍 공간 최적화 과정을 시각화한다.
소수의 프로토타입(열)만이 입력 패치(행)를 재프로그래밍하는 데 참여하는 것을 서브플롯(e)에서 발견했다. 또한, 패치들은 프로토타입의 다양한 조합을 통해 다른 표현의 경우의 수를 가져온다. 이는 다음을 나타낸다: (1) 텍스트 프로토타입은 언어 단서를 요약하는 방법을 학습하며, 소수의 프로토타입만이 지역 시계열 패치의 정보를 표현하는 데 매우 관련이 높은 것이다. 서브플롯(f)에서 무작위로 10개를 선택하여 이를 시각화하고, 결과는 시계열 속성을 설명하는 단어들(즉, 단어 세트 1과 2)에 높은 관련성을 제안한다; (2) 패치들은 보통 다른 기저 의미를 가지고 있어, 다른 프로토타입을 사용하여 표현할 필요가 있다.
Reprogramming Efficiency
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] An Image Is Worth 16x16 Words:Transformers For Image Recognition At Scale (0) | 2024.04.01 |
|---|---|
| [논문 리뷰] Are Transformers Effective for Time Series Forecasting? (0) | 2024.04.01 |
| [논문 리뷰] TS2Vec: Towards Universal Representation of Time Series (0) | 2024.03.25 |
| [논문 리뷰] MASK R-CNN (0) | 2024.03.25 |
| [논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network (0) | 2024.03.20 |