
티스토리 뷰
[논문 리뷰] An Image Is Worth 16x16 Words:Transformers For Image Recognition At Scale
hyuna_engineer 2024. 4. 1. 13:33
NLP 분야에서 쓰이던 Transformer가 CV 분야에서 결합했다고 생각하면 된다. ViT(Vision Transformer)는 Image를 CNN이 아닌 Transformer에 넣는 것이라 생각하면 된다.
1. Introduction
Transformer를 활용 NLP 분야는 계속해서 발전했지만, CNN은 아직도 높은 ResNet에 그쳐서 좋은 성능을 가진 획기적인 모델이 나오지 못했다. CNN에 self attention을 추가해서 시도하기도 했지만, 여전히 성능이 그저 그랬다. 그렇기에 image를 작은 Patches로 쪼개고 이를 transformer에 넣어보는 건 어떨까라고 저자들은 생각하며 시도했다. CNN과 달리 Transformer는 locality나 translation equivariance와 같은 inductive bias가 부족하다. 또한, 적은 데이터 셋으로는 좋은 성능을 내지 못하는 단점도 있다. (<-이거는 아직도 한계점이긴 한 듯) 그래서 transformer에 넣어 실험을 진행할 14 million~300 million 정도의 큰 스케일로 훈련시켰으며, 그 결과는 잘 나왔다고 한다. 본격적으로 구조를 보자.
2. Related Works
이와 관련된 연구들을 우선 보자.
Transformers는 NLP 분야에서 각광받는 모델로 유명하다. Large Transformer-based model; BERT 같은 경우 self-supervised pre-training task를 denoising해서 훈련시킨다.
image에 따른 self-attention 활용하는 각 픽셀이 다른 픽셀에 매칭되어야 한다. 사실 이전에도 image를 Transformer에 적용해보는 노력은 이어져 왔다.
1. 각 query의 local neighborhood에 self-attention을 적용했었고, 이런 local multi-head 내적은convolution을 대체하긴 했다.
2. Sparse Transformers는 이미지에 적용 가능하게 하기 위해 global self-attention에 근사치를 사용. 중요하거나 의미 있는 토큰 쌍만을 선택하여 Attention을 수행함.
3. scale attention의 alternative way로 block마다 attention 적용하기, axis에 attention 적용하기
3.이 무슨 의미인지 잘 모르겠어서 gpt한테 코드 예시를 들어달라고 부탁했음.
Block attention
import torch
import torch.nn as nn
class BlockAttention(nn.Module):
def __init__(self, block_size):
super(BlockAttention, self).__init__()
self.block_size = block_size
self.attention = nn.MultiheadAttention(embed_dim=64, num_heads=8)
def forward(self, x):
# x: [batch_size, seq_len, embedding_dim]
b, seq_len, d = x.shape
blocks = x.view(b, seq_len // self.block_size, self.block_size, d) # 블록으로 나누기
blocks = blocks.permute(1, 0, 2, 3).contiguous().view(-1, self.block_size, d) # 각 블록을 Attention에 넣기
# 각 블록에 Attention 적용
attended_blocks, _ = self.attention(blocks, blocks, blocks)
# 블록을 다시 원래 형태로 합치기
attended_blocks = attended_blocks.view(seq_len // self.block_size, b, self.block_size, d)
attended_blocks = attended_blocks.permute(1, 0, 2, 3).contiguous().view(b, seq_len, d)
return attended_blocks
# 예제 입력
x = torch.rand(1, 16, 64) # 1개의 시퀀스, 16개의 토큰, 64차원 임베딩
block_attention = BlockAttention(block_size=4)
output = block_attention(x)
print(output.shape) # (1, 16, 64)
Axis attention
import torch
import torch.nn as nn
class AxialAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(AxialAttention, self).__init__()
self.row_attention = nn.MultiheadAttention(embed_dim, num_heads)
self.col_attention = nn.MultiheadAttention(embed_dim, num_heads)
def forward(self, x):
# x: [batch_size, height, width, embedding_dim]
b, h, w, d = x.shape
# 가로 (Row-wise) Attention
x = x.permute(0, 2, 1, 3).reshape(b * w, h, d) # (batch_size * width, height, embedding_dim)
x, _ = self.row_attention(x, x, x)
x = x.view(b, w, h, d).permute(0, 2, 1, 3) # 원래 형태로 복원
# 세로 (Column-wise) Attention
x = x.permute(0, 1, 3, 2).reshape(b * h, w, d) # (batch_size * height, width, embedding_dim)
x, _ = self.col_attention(x, x, x)
x = x.view(b, h, d, w).permute(0, 1, 3, 2) # 원래 형태로 복원
return x
# 예제 입력
x = torch.rand(1, 4, 4, 64) # (batch_size, height, width, embedding_dim)
axial_attention = AxialAttention(embed_dim=64, num_heads=8)
output = axial_attention(x)
print(output.shape) # (1, 4, 4, 64)
ViT 모델은 다음 논문의 모델을 많이 참고했다 한다.
https://arxiv.org/abs/1911.03584
On the Relationship between Self-Attention and Convolutional Layers
Recent trends of incorporating attention mechanisms in vision have led researchers to reconsider the supremacy of convolutional layers as a primary building block. Beyond helping CNNs to handle long-range dependencies, Ramachandran et al. (2019) showed tha
arxiv.org
여기서 input image로부터 patch size 2x2를 추출하고, top에는 full self-attention 적용을 진행했다. small-resolution(낮은 해상도)에도 적용 가능하게끔 모델을 수정했고, medium-resolution(중간 해상도)에서도 가능하게끔 했다. ViT는 여기서 더 나아가 큰 데이터셋으로 pretraining 진행함으로써 CNN SOTA랑 맞먹을 수 있게끔 만들었다고 한다. 그리고 제목에서 알 수 있다시피 16x16으로 잘라서 활용한 듯.
특정 downstream task을 해결하기 위해 노력했었음.
CNN + self-attention을 하려는 노력도 많았다. image classificaiton을 위해 feature map을 변형시키거나, output을 self-attention에 적용시키는 등..
image GPT(iGPT) 또한 image의 해상도와 color space를 축소하고, transformer를 사용해서 나타냈다. 이 모델은 unsupervised 으로 생성모델로서 훈련이 되고, 성능 또한 ImageNet의 72% 정도만을 달성했다.
ViT의 특징은 기존 연구는 ResNet(CNN 기반)을 사용했지만, ImageNet의 dataset보다 더 많은 양의 image recognition을 진행했다.
3. Method
우선 ViT 구조는 다음과 같다.

NLP Transformer 구조와 이에 대한 계산에 대한 효율성을 고려하여 ViT는 최대한 transformer와 비슷하게 구조를 구축했다.
3.1. Vision Transformer ( ViT )
원래 기존 transformer의 input으로 token embedding이 된 1D sequences이다. 2D image로 다루기 위해서는이 3D
Transformer은 size D 만한 latent vector size를 다루는데, flatten 시키고, D 차원만큼 다시 mapping해준다.
위의 사진처럼 말이다.
BERT의 '[class]' 토큰과 유사하게, 학습시킬 임베딩을 임베딩된 패치의 시퀀스의 앞에 추가한다. 즉,
- Class Token (x_{class})
- Transformer 입력의 맨 앞에 추가되는 학습 가능한 토큰.
- Transformer를 거친 후, 최종 출력에서 이미지 전체를 대표하는 Global Representation으로 사용됨.
- Classification Head
- Class Token의 최종 출력(z0Lz_{0}^{L})을 입력으로 받아 이미지 분류를 수행.
- Pre-training: MLP (Multi-Layer Perceptron, 다층 신경망)를 사용
- Fine-tuning: 단일 선형 레이어(Linear Layer)를 사용
정리하면, '[class]' 토큰은 입력 시퀀스의 시작에 추가되는 특수한 임베딩으로, 주로 문장이나 문서의 전체적인 의미를 포착하는 데 사용됨. 이 문장에서는 이 개념을 이미지 처리에 적용하여, 변환된 이미지 패치 시퀀스의 시작에 학습 가능한 '[class]'와 유사한 임베딩을 추가. 이 임베딩은 Transformer 모델을 통과한 후 최종 이미지의 표현을 형성. 분류 헤드는 사전 학습 시에는 하나의 은닉층을 가진 MLP로 미세 조정 시에는 단일 선형 층으로 구현된다.
Position embedding 또한 patch information에 추가되는데, 이는 positional information을 유지하고 싶을 때 그렇게 한다. 저자는 1D position embedding을 썼는데, 2D를 안 쓴 이유는 뒤에 나온다.
Transformer encoder는 multihead self-attention의 바꿀 수 있는 layer로 구성되고, MLP LayerNorm은 각 블록 전에 적용된다. 또한 여기에 있는 Residual block은 우리가 흔히 아는 transformer의 원리와 비슷하다고 생각하면 된다. 이에 관련된 식은 다음과 같다.
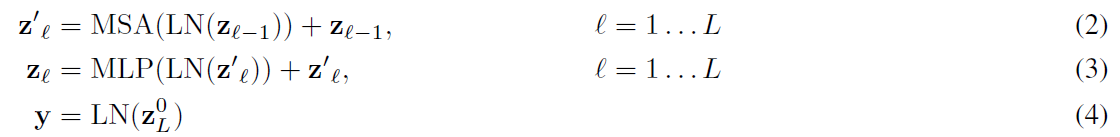
Inductive bias
ViT는 CNN보다 less image inductive bias를 가진다. CNN에서는 locality, two-dimensional neighborhood structure, 그리고 translation equivariance이 모델 전체의 각 계층에 내장되어 있음. -> 이게 무슨 말이냐면, CNN은 필터로 이미지 부분 연산 진행, 그렇게 되면서 2D로 다루고, 필터가 이미지 전반에 동일하게 적용된다는 말 그냥 CNN 특징 얘기한 거임.
반면에 ViT에서는 MLP 계층만이 지역적이고 이동 동등성을 가지며, self-attention layer는 전역적으로 존재한다.
이렇게 ViT가 inductive bias가 부족한 이유는 MLP는 fully connected이기 때문이며, 이런 구조는 픽셀에 대한 가중치로 연산을 진행하기에 convolution 연산과는 달리 translation equivariance 특성이 사라진다.
Translation Equivariance
필터가 이미지 모든 부분에 동일하게 적용됨.
two-dimensional structure
이미지의 픽셀값을 나타내는 2차원 그리이다. 이는 transformer에 input image를 어떻게 제시하는지 알려준다.
Hybrid architecture
CNN+transformer 구조로 CNN feature map에서 추출된 patch에 정사영한 E(위의 Eq (1))을 적용시킨다. patch 크기는 1x1이므로 feature map의 spatial dimension을 flatten시키고, transformer dimension으로 정사영시킴으로써 이 크기를 가진다.
3.2 fine-tuning and higher resolution
ViT는 거대 데이터셋을 이용하기에, 이후 object detection, object segmentation 등에 미세 조정을 하기 위 downstream task를 진행한다. pre-trained prediction을 제거하고,
- 새로운 Fine-tuning Head 추가
- 새로운 Feedforward Layer를 추가.
- Zero-initialized (0으로 초기화): 초기에는 모든 가중치가 0으로 설정.
- 차원: D × K
- D: Transformer의 출력 차원
- K: Fine-tuning 데이터셋의 클래스 수
이러한 미세 조정은 고해상도의 image에서 좋은 결과를 낸다. 만약 고해상도 이미지를 feedforward 시킨다면 patch size를 같게 유지하게 한다. 이는 sequence 길이에서 좋은 성능을 낸다. ViT는 임의의 시퀀스에 대해서도 처리가 가능하며, pre-trained된 position embedding은 그 자체로는 의미가 없다. 그러므로 우리는 이런 embedding에 대해 2D interpolation을 진행하며 변형을 가하면서 성능을 높이고자 했다.
4. Experiments
위에서 얘기한 cnn feature map+transformer와 ResNet 등을 성능 비교를 했다. ViT가 계산량 측면에서도 좋은 결과를 가져왔고, SOTA 모델보다 pre training 또한 적게 해도 좋은 결과를 냈다. self-supervised를 진행한 실험에서도 좋은 결과를 냈다.
4.1 SetUp
Dataset
모델 크기를 보기 위해
1) ILSVRC-2012 ImageNet dataset인데 1k classes & 1.3M images 데이터셋
2) ImageNet 21k classes & 14M images
3) JFT 18k classes & 303M 고해상도 데이터셋
pretraining하면서 downstream task의 test sets과 중복 안 되게끔 구성했다.
19-task VTAB classification suite (Zhai et al., 2019b)이 대해서도 비교를 진행했다. VTAB를 low-data transfer로 diverse tasks에 대해서 잘 처리하는지에 대해 평가했다. task마다 1000 training examples을 이용했다. task는 세 가지 그룹으로 쪼개졌다. (1) Natural – tasks, (2) Specialized – medical, satellite imagery, (3) Structured – tasks <-localization 요구하는 data
결과는 다음과 같다.
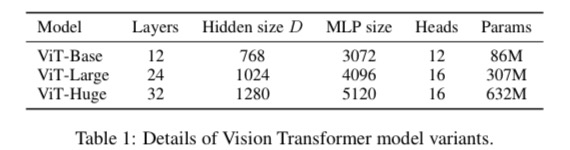
Model Variants
BERT (Devlin et al., 2019)를 기반으로 한 ViT 성능 비교. 위의 표에서 “Base” and “Large” models 은 BERT에서 온 것, “Huge” model 또한 추가.
ViT-L/16 이란 “Large” variant 인데 16 × 16 input patch size을 가진 것을 의미한다. patch size가 제곱 배로 커질수록 transformer sequence length는 반비례 관계로 줄어든다. 그렇기에 smaller patch size는 계산량이 많다.
Baseline CNN 마련할 때 ResNet (He et al., 2016)을 이용했다. Batch Normalization layers는 Group Normalization로 대체했고, standardized convolutions (Qiao et al., 2019)을 이용했다. 이런 변형은 정보 전달(transfer) 능력을 향상 시켰고, 이러한 변형된 모델을 “ResNet (BiT)“라고 이름 붙였다.
다른 sequence 길이에서도 훈련이 잘 되는지 확인하기 위해 다음 4가지를 진행했다. (i) 기본 ResNet50의 stage 4 의 결과를 이용하거나 (ii) stage 4를 제거 후 stage 3에 이 stage 4의 layer 수만큼을 추가하는 방법을 택하고, stage 3의 결과를 이용하는 방법을 택했다. 또한, (ii) 4x longer sequence length을 넣었을 때의 결과 등 이렇게 확인했다.
Training & Fine-tuning.
ResNets인데 Adam을 적용한 모델로 훈련을 해다. 자세하게 얘기하자면, β1 = 0.9, β2 = 0.999에 batch size가 4096이고, weight decay(가중치 감소)가 0.1이 되게끔 세팅했다. 학습 초기에 학습률을 점진적으로 증가시키는 '워밍업(warmup)' 단계와, 이후 학습률을 점진적으로 감소시키는 '감소(decay)'을 이용한 train 방법을 적용했다.
Fine-tuning 으로 모멘텀이 적용된 SGD에, batch size 512를 사용했다. 고해상도 데이터에 대해서도 모델을 적용해보다. 다음 표를 참고하자.

Metrics
downstream datasets, 사전 학습(pre-training) 단계 이후, 특정 task이나 목표를 위해 사용되는 데이터셋을 사용했는데, few-shot 또는 fine-tuning accuracy 또한 나와있다. Few-shot accuracy 측정은 훈련 이미지의 일부 집합의 (고정된) 표현을 {-1, 1}^K 타겟 벡터로 매핑하는 정규화된 최소 제곱 회귀를 이용해서 이루어진다. 이 공식화는 닫힌 형태에서 정확한 해를 찾을 수 있게 해준다. 주로 미세 조정 성능에 초점을 맞추지만, 미세 조정이 너무 비용이 많이 들 때는 빠른 평가를 위해 선형으로 된 적은 수 샘플 정확도를 가끔 사용한다.
4.2 SOTA와 비교
ViT-H/14 & ViT-L/16 을 다음에 대해 비교
(1) Big Transfer (BiT) - large ResNets을 supervised transfer learning 으로 수행한 모델.
(2) Noisy Student - 거대 EfficientNet trained로 ImageNet애서 semi-supervised learning을 이용하고, label이 제거된 JFT- 300M 데이터셋을 이요한 모델.
(2) +ImageNet & (2) + 가 요즘 SOTA 모델이다. TPUv3 hardware에서 실행하였다.
ImageNet-21k dataset 을 이용한 ViT-L/16 model pre-trained 이 대부분의 데이터셋에서도 좋은 성능을 보였다.
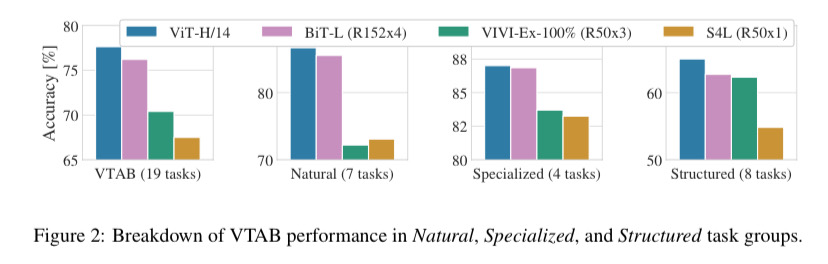
4.3 PRE-TRAINING DATA REQUIREMENTS
ViT는 large JFT-300M dataset에 높은 성능을 보인다.
vision에 대해서 다른 타 모델보다 적은 inductive bias를 지니며, 두 가지 데이터셋에 대해서 실험을 진행했다. 그 전에 여기서 inductive bias란? 모델의 parameter와 같이 모델이 학습하면서 얻는 학습의 방향성, 특정한 가정을 하게 만드는 경향성을 의미한다.
데이터셋의 크기가 중요한가? 두 가지 방법 수행
1. pre-train ViT models <- ImageNet, ImageNet-21k & JFT- 300M 이미지 세트 적용. 작은 데이터셋에서도 좋은 성능을 보이기 위해 3가지 regularization parameters를 정했다. 이는 (1) weight decay (2) dropout (3) label smoothing이 있다.
이에 대한 결과는 다음과 같다.
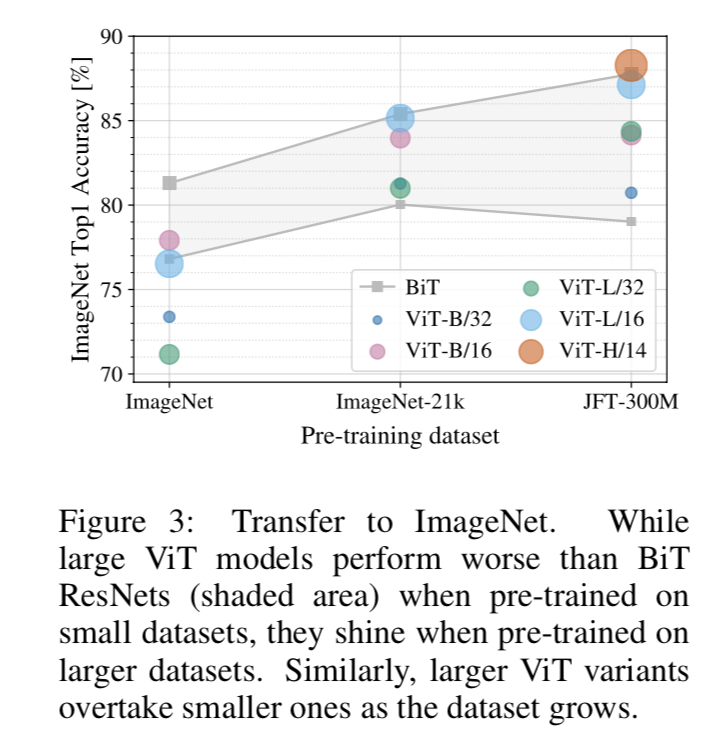
smallest dataset인 ImageNet으로 훈련했을 때는 ViT-Large model이 ViT-Base model에 비해 underperform 됐다.
2. 9M, 30M, 90M, JFT- 300M dataset에 대해 random subsets을 추출했다. 이 method 경우 작은 데이터셋에 대해서는 정규화를 진행하지 않았다. 대신 모든 세팅에 같은 hyper-parameters를 적용했다. 각 모델의 순수한 특성을 데이터셋으로 비교한다고 볼 수 있다. 실험 진행 도중 가장 좋은 결과가 나오면 멈추기도 했고, few-shot linear accuracy 결과를 사용하기도 했다.
Vision Transformers은 적은 데이터셋에서는 overfitting이 다른 모델(ResNet 등) 심했다. 하지만, parameter 수와 같이 computing, 계산 측면에서는 이득이 많았다.
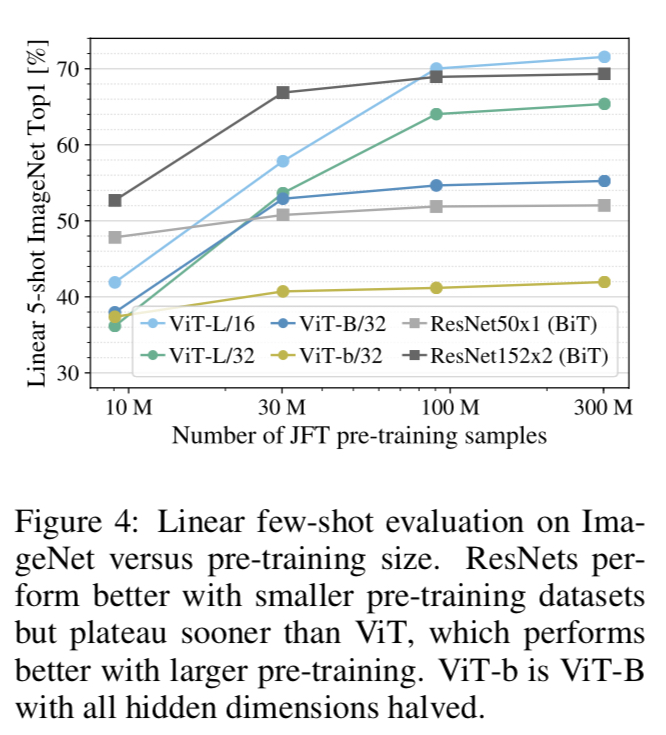
4.4 Scaling study
JFT-300M에서의 전이 성능을 평가하여 다양한 모델의 크기(scaling)에 대한 연구를 수행했습니다. 모델은 7개의 ResNets, R50x1, R50x2, R101x1, R152x1, R152x2를 7 에포크 동안 사전 학습시켰고, R152x2와 R200x3는 14 에포크 동안 사전 학습시켰다.
Vision Transformers, ViT-B/32, B/16, L/32, L/16은 7 에포크 동안, 그리고 L/16과 H/14는 14 에포크 동안 사전 학습시켰고, 5개의 하이브리드, R50+ViT-B/32, B/16, L/32, L/16은 7 에포크 동안, 그리고 R50+ViT-L/16은 14 에포크 동안 사전 학습시켰다.(하이브리드의 경우, 모델 이름 끝의 숫자는 패치 크기가 아닌 ResNet 백본의 총 다운샘플링 비율을 의미합니다).
결과는 다음과 같다.

여기서 몇 가지 패턴을 관찰할 수 있다.
첫째, Vision Transformers는 성능/계산 트레이드오프에서 ResNets를 압도한다. ViT는 같은 성능을 달성하기 위해 약 2 - 4배 적은 계산을 사용한다.(5개 데이터셋 평균).
둘째, 하이브리드는 작은 계산에서는 ViT를 약간 앞서지만, 큰 모델에 대해서는 차이가 없다. 크기에 관계없이 convolutional local feature가 ViT를 결과 처리를 도와줄 것이기 때문이다.
셋째, Vision Transformers는 시도된 범위 내에서 포화 상태에 이르지 않는 것으로 보인다.
4.5 Inspecting Vision Transformer
Vision Transformer가 이미지 데이터를 어떻게 처리하는지 이해하기 위해, internal representation을 분석하자.
Vision Transformer의 첫 번째 레이어는 flatten한 패치들을 낮은 차원의 공간으로 선형적으로 투영(Eq. 1)하는데, 그림 7(왼쪽)은 모델이 학습한 임베딩 필터의 주요 성분을 보여주며, 이 성분들은 각 패치 내의 미세 구조의 저차원 표현을 위한 함수들과 닮았다고 한다.

투영 후, 위치 임베딩이 패치 표현에 추가된다. 그림 7(가운데)는 모델이 이미지 내의 거리를 위치 임베딩의 유사성에 인코딩하는 방법을 학습하는 과정을 나타낸다. 여기서 가까운 패치들은 더 유사한 위치 임베딩을 가짐을 알 수 있다. 더 나아가, 같은 행/열에 있는 패치들은 유사한 임베딩을 가진다.
self-attention은 ViT가 가장 낮은 레이어에서도 전체 이미지에 걸쳐 정보를 통합할 수 있게 한다. 네트워크가 이 self-attention 이용도(?)를 조사한다. 구체적으로, 어텐션 가중치를 바탕으로 이미지 공간의 평균 거리를 계산한다(그림 7, 오른쪽). 이 "어텐션 거리" = CNN에서의 receptive field size.
분석한 결과 다음을 도출할 수 있다.
1. 일부 헤드가 가장 낮은 레이어에서 이미지의 global한 정보를 이미 주목을 하는 것을 알 수 있다. 반대로 어떤 어텐션 헤드는 작은 attention distance를 가지며, local한 정보를 가지곤 한다. CNN의 Convolutional Layers이 수행하는 역할과 유사.
Attention Distance: 특정 Attention Head가 얼마나 넓은 범위의 토큰(패치)에 주의를 기울이는지를 의미
2. Figure 7의 오른쪽을 보면, hybrid model에서는 local attention이 덜 뚜렷하다. ResNet의 초기 convolutional layer에서 이미 local 특징을 먼저 처리하고, transformer는 더 global context 학습해서 그렇다고 한다.
3. 어텐션 거리는 네트워크 깊이와 함께 증가합니다. 전반적으로, 모델이 분류에 의미적으로 관련된 이미지 영역에 주목한다는 것을 알 수 있다.

+) Receptive field 개념 까먹어서 다시 적어봄


4.6 Self supervision
transformer는 NLP(자연어 처리) 작업에서 인상적인 성능을 보여주었다. 대규모 self supervision 사전 학습에서도 차장을 일으켰다. 또한 BERT에서 사용된 마스크 언어 모델링 작업을 모방하여 self supervision을 위한 마스크 패치 예측에 대한 예비 탐색을 수행했다. self supervision 사전 학습을 통해, 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하여, 처음부터 훈련시키는 것보다 2%의 상당한 개선을 보였지만, 감독된 사전 학습에 비해 여전히 4% 뒤처진다.
5. Conclusion
결론적으로, 저자는 이미지 인식 CV분야와 트랜스포머, NLP분야를 접목시켜 실험해본 것이다. 컴퓨터 비전에서 self attention만 시용했지, 전체적인 구조 자체를 NLP의 transformer를 직접으로 이용한 적은 처음인 것이다. 이미지를 패치의 시퀀스로 해석하고 NLP에서 사용되는 표준 트랜스포머 인코더로 처리한다. 간단하지만 확장 가능성 높은 이 전략은 대규모 데이터셋에서 사전 학습과 결합될 때 놀랍도록 잘 작동하여, Vision Transformer가 많은 이미지 분류 데이터셋에서 최신 기술을 맞추거나 능가하면서도 사전 훈련 비용이 상대적으로 저렴한 장점이 있다.
Limitation
(1) ViT를 탐지 및 분할과 같은 다른 컴퓨터 비전 작업에 적용하는 것은 아직 어렵다.
(2) self-supervision 사전 학습 방법을 계속 찾아야 함. 즉, 대규모와 적은 데이터셋으로의 self supervision 학습에는 여전히 큰 차이가 있다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] PSNet: A Style Transfer Network for Point Cloud Stylization on Geometry and Color (1) | 2025.01.13 |
|---|---|
| [논문 리뷰] Are Transformers Effective for Time Series Forecasting? (0) | 2024.04.01 |
| [논문 리뷰] TIME-LLM: TIME SERIES FORECASTINGBY REPROGRAMMING LARGE LANGUAGE MODELS (1) | 2024.03.31 |
| [논문 리뷰] TS2Vec: Towards Universal Representation of Time Series (0) | 2024.03.25 |
| [논문 리뷰] MASK R-CNN (0) | 2024.03.25 |