
티스토리 뷰
[논문 리뷰] TS2Vec: Towards Universal Representation of Time Series
hyuna_engineer 2024. 3. 25. 19:311. Introduction
임의의 semantic level에서도 time series의 전체적인 특성을 표현하게 하는 것이 목표다. 이 모델은 contrastive learning을 augmented context views을 넘어hierarchical way에서도 가능하게끔 하는 것이 목표다. time series의 전체적인 특성을 담는 것은 쉽지 않다. 예전 연구들은 전체적인 특성을 담기 위해 전체 segment를 한 번에 넣고 전체적인 특성을 담고자 했다. 최근에는 contrastive loss을 활용해서 inherent structure of time series을 배우게 하고 있다. 여기에는 문제점이 있다.
1. instance-level representations은 시계열 예측과 이상 탐지와 같이 세밀한 표현이 필요한 작업에 적합하지 않을 수 있다. 이러한 종류의 작업에서는 특정 타임스탬프나 연속 데이터 일부분에서 대상을 추론해야 하며, 전체 시계열의 거친 표현만으로는 만족스러운 성능을 달성하기에 부족하다.
2. 이미 존재하는 method의 일부만 다양한 세분성을 가진 multi-scale 맥락 정보를 구별합니다. 하지만, 이들은 scale 불변성 속성을 담고 있지는 못한다.
3. 대부분 방법들이 CV, NLP 분야에서 차용한 것이기에 시계열 데이터에 적합하지 않은 점들이 많다.
이를 보완한 TS2Vec는 모든 semantic level에서의 representation learning을 가능하게 한다. 계층적으로 긍정, 부정 샘플들을 나누고, sub-series는 max pooling으로 특징 추출한다. 이 방법은 모델이 시간 데이터를 다양한 해상도에서 분석해 맥락 정보를 잡아내고, 어떤 세밀함에도 미세한 표현을 만들 수 있게 합니다. 게다가, TS2Vec에서 사용된 대조 목표는 증강된 맥락 뷰, 즉 두 개의 증강 맥락에서 동일한 부분 시리즈가 일관된 표현을 가져야 한다는 점에 기반을 두고 있습니다. 이러한 방식으로, 변환 및 자르기에 대한 불변성 같은 바람직하지 않은 선험적 가정을 추가하지 않고도 각 부분 시리즈에 대해 견고한 맥락적 표현을 얻을 수 있습니다.
임의의 부분 시계열 데이터에 대해 다양한 semantic-level에서 문맥적 표현을 학습하는 TS2Vec은 시계열 분야의 모든 종류의 작업에 대해 유연하고 보편적인 표현 방법을 제공하는 첫 번째 작업이다. 여기에는 시계열 분류, 예측, 이상 탐지 등이 포함되지만 이에 국한되지 않고 활용될 수 있다.
이 목적을 위해 두 가지의 시사점이 있다. 첫째, 다중 스케일 문맥 정보를 포착하기 위해 각 instance마다, 그리고 각 시간적 차원 모두에서 계층적 대조 방법을 사용한다. 둘째, 긍정 쌍 선택을 위한 문맥 일관성을 제안한다. 이전의 최신 기술과 달리, 다양한 분포와 규모를 가진 시계열 데이터에 더 적합하다. 광범위한 분석은 TS2Vec이 누락된 값이 있는 시계열에 대한 강인함을 입증하고, 계층적 대조와 문맥 일관성의 효과는 소거 연구를 통해 검증되었다.
TS2Vec은 분류, 예측, 이상 탐지를 포함한 세 가지 벤치마크 시계열 작업에서 기존의 최고 수준 기술을 능가한다. 예를 들어, 우리의 방법은 분류 작업에 대한 비지도 표현의 최고 SOTA와 비교하여 UCR 데이터셋 125개에 대해 평균 2.4% 정확도를, UEA 데이터셋 29개에 대해 3.0% 향상시킨다.
2. Model Architecture

2.1.
전체적인 구조는 위의 사진과 같다.
하나의 sub series 두 개의 overlapping sub series 추출 후, 이는 이 series의 일관성을 부여하기 위함이다. 이러한 raw data가 encoder 구조의 input으로 들어가고, temporal & instance-wise contrastive loss에 의해 최적화가 진행된다. encoder
1. input projection layer
2. time step masking module
3. dilated CNN module
1. input x_i를 고차원 latent vecotr로 정사영 시켜주는 역할을 하는 fully connected layer이다.
2. 이 모듈은 임의로 선택된 타임스탬프에서 latent vector를 마스킹하여 확장된 문맥 뷰를 생성한다. 우리가 원시 값이 아닌 latent vector를 마스킹하는 이유는 시계열 데이터의 값 범위가 무한할 수 있으며, 원시 데이터에 대한 특별한 토큰을 찾는 것이 불가능하기 때문이다. 이 설계의 타당성을 부록에서 더 자세히 증명할 것입니다.
3. 열 개의 잔여 블록을 가진 확장된 CNN 모듈이 각 타임스탬프에서 문맥적 표현을 추출하기 위해 적용된다. 각 블록은 확장 파라미터(2l을 l번째 블록에 대해)를 가진 두 개의 1-D 컨볼루션 레이어를 포함한다. 확장된 컨볼루션은 다양한 도메인에 대해 큰 수용 필드를 가능하게 한다. 이후 실험에서 자세히 설명할 것이다.
2.2 Contextual Consistency
contrastive learning에서 positive pair의 구축은 중요하다. 이 positive pair를 선택하는 전략으로 논문에서는 다음 3가지 기준을 세워 고려했었다.
- subseries consistency
- Temporal consistency
- Transformation consistency
이 3가지 전략은 data 분류가 잘 되었을 때를 가정하며, 이러한 분류 작업은 time series data에 적합하지 않다.
이유로, figure 3-(a)를 보면, sub series의 패턴이 다시 시작할 떄, subseries의 일관성 (1 감소)이 떨어진다. 또한, figure 3-(b)를 보면, outlier 값이 튀면, temporal consistency가 감소한다. (2감소) 이러한 이유 때문에 저자는 새로운 전략을 내세웠다. Contextual consistency 이다.
이는 두 개의 (확장된) context가 같은 timestep 시점은 positive pair로 취급한다. 참고로 context는 시계열 데이터에 timestep masking과 random cropping을 통해 생성된다. 여기서 2가지 중요한 점이 있다.
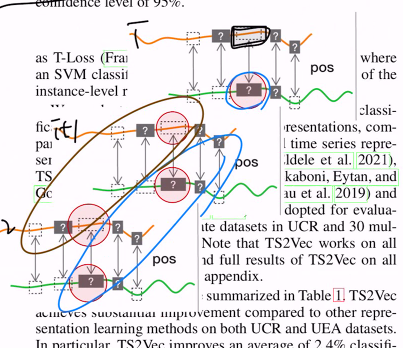
1. masking과 cropping은 time series의 길이를 바꾸면 안 된다.
2. 각 time step마다 서로 다른 문맥에서는 문맥을 재구성하게 하면서 representation learning의 견고함을 증가시켰다.
<Timestamp Masking>
랜덤하게 timestamp을 masking 시켜서, 새로운 context view를 생성한다. 구체적으로 Input projection layer를 통과한 latent vector를 time 축에 binary mask 축과 함께 나열시킨다. 이때, 랜덤하게 할 때, 베르누이 분포 (p=0.5)를 따른다. enocder의 every forward pass마다 sampled 시킨다.
<Random cropping>
새로운 문맥 생성을 위해 random cropping이 쓰인다.
2.3 Hierachical Contrasting
다양한 scale에서도 encode가 학습이 가능하게 hierarchical contrastive loss가 이를 도와주며, 이러한 계산 알고리즘은 밑에 나와 있다. 이렇게 함으로써 data의 세밀함을 담았다. instance-wise와 temporal contrastive loss가 time series 분포 encode을 위해 쓰이며, 이는 세밀한 level까지의 분석이 가능하게 했다.

<Temporal Contrastive Loss>
시간을 넘어서 discriminative-representation을 학습하기 위해, TS2Vec은 입력 시계열 데이터의 두 가지 view에서 같은 타임스탬프의 표현을 긍정적인 것으로 취급하며, 동일한 시계열 데이터에서 서로 다른 타임스탬프의 표현을 부정적인 것으로 취급합니다. 여기서 i는 입력 시계열 샘플의 인덱스이고 t는 타임스탬프입니다. 그러면

<Instacne-wise Contrastive Loss>
이에 관련한 식은 다음과 같다.

이들을 합쳐서 다음 식으로 loss를 구했다.
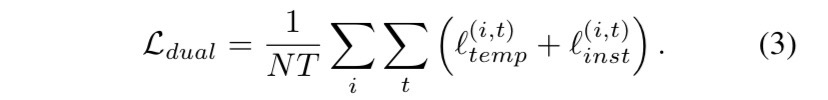
3. Experiment
3.1 Time series classification
time series가 labeling된 datset으로 실행. 이 time series classification을 실행했을 때, T-Loss, TS-TCC와 비교했으며, 결과는 다음과 같다.

3.2 Time Series Forecasting
결과는 다음과 같다. Table 2 & Table 3



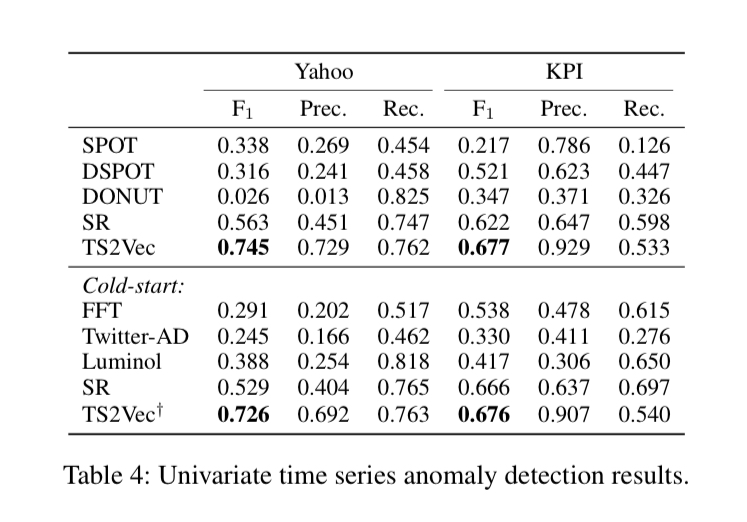
3.3 Time Series Anomaly Detection
Table 4와 Table 5 참고

4. Conclusion
이 논문은 시계열 데이터에 대한 보편적인 표현 학습 프레임워크인 TS2Vec을 제안한다. TS2Vec은 확장된 문맥 뷰 내에서 스케일 불변 표현을 학습하기 위해 계층적 대조를 적용하며, 학습된 표현을 시계열 관련 작업 3가지(시계열 분류, 예측 및 이상 탐지 포함)에서 평가한 결과, TS2Vec의 보편성과 효과성이 입증되었다. 또한, TS2Vec은 불완전한 데이터를 입력받을 때 안정적인 성능을 제공하는데, 이때 계층적 대조 손실과 타임스탬프 마스킹이 중요한 역할을 한다. 미처 설명하지 못했던, ablation study의 visualization of representative learning은 TS2Vec이 시계열 데이터의 동적 특성을 포착하는 능력을 확인시켜 준다. 이 섹션에서 제안된 구성 요소의 효과성을 증명하낟. TS2Vec 프레임워크는 일반적이며, 향후 다른 도메인에도 적용될 잠재력을 가지고 있다. 이를 발전시키면 더 좋은 모델이 나올 것이다.
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Are Transformers Effective for Time Series Forecasting? (0) | 2024.04.01 |
|---|---|
| [논문 리뷰] TIME-LLM: TIME SERIES FORECASTINGBY REPROGRAMMING LARGE LANGUAGE MODELS (1) | 2024.03.31 |
| [논문 리뷰] MASK R-CNN (0) | 2024.03.25 |
| [논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Network (0) | 2024.03.20 |
| [논문 리뷰] Fast R-CNN (0) | 2024.03.19 |